Wednesday, December 23, 2009
Announcing our Q4 Research Awards
We do a significant amount of in-house research at Google, but we also maintain strong ties with academic institutions globally, pursuing innovative research in core areas relevant to our mission. One way in which we support academic institutions is the Google Research Awards program, aimed at identifying and supporting world-class, full-time faculty pursuing research in areas of mutual interest.
Our University Relations team and core area committees just completed the latest round of research awards, and we're excited to announce them today. We had a record number of submissions, resulting in 76 awards across 17 different areas. Over $4 million was awarded — the most we have ever funded in a round.
The areas that received the highest level of funding for this round were systems and infrastructure, machine learning, multimedia, human computer interaction, and security. These five areas represent important areas of collaboration with university researchers. We're also excited to be developing more connections internationally. In this round, over 20 percent of the funding was awarded to universities outside the U.S.
Some exciting examples from this round of awards:
Ondrej Chum, Czech Technical University, Large Scale Visual Link Discovery. This project addresses automatic discovery of visual links between image parts in huge image collections. Visual links associate parts of images that share even a relatively small, but distinctive, visual information.
Bernd Gartner, ETH Zurich, Linear Time Kernel Methods and Matrix Factorizations. This project aims to derive faster approximation algorithms for kernel methods as well as matrix approximation problems and leverage these two promising paradigms for better performance on large scale data.
Dawson Engler, Stanford University, High Coverage, Deep Checking of Linux Device Drivers using KLEE + Under-constrained Execution Symbolic execution. This project extends the recently built KLEE, a tool that automatically generates test cases that execute most statements in real programs, so that it allows automatic, deep checking of Linux device drivers.
Jeffrey G. Gray, University of Alabama at Birmingham, Improving the Education and Career Opportunities of the Physically Disabled through Speech-Aware Development Environments. This project will investigate the science and engineering of tool construction to allow those with restricted limb mobility to access integrated development environments (IDEs), which will support programming by voice.
Xiaohui (Helen) Gu, North Carolina State University, Predictive Elastic Load Management for Cloud Computing Infrastructures. This project proposes to use fine-grained resource signatures with signal processing techniques to improve resource utilization by reducing the number of physical hosts required to run all applications.
Jason Hong and John Zimmerman, Carnegie Mellon University, Context-Aware Mobile Mash-ups. This project seeks to build tools for non-programmers to create location and context-aware mashups of data for mobile devices that can present time- and place-approriate information.
S V N Vishwanathan, Purdue University, Training Binary Classifiers using the Quantum Adiabatic Algorithm. The goal of this project is to harness the power of quantum algorithms in machine learning. The advantage of the new quantum methods will materialize even more once new adiabatic quantum processors become available.
Emmett Witchel and Vitaly Shmatikov, University of Texas at Austin, Private and Secure MapReduce. This project proposes to build a practical system for large-scale distributed computation that provides rigorous privacy and security guarantees to the individual data owners whose information has been used in the computation.
Click here to see a full list of this round’s award recipients. More information on our research award program can be found on our website.
Wednesday, December 16, 2009
Teaching a Computer to Understand Japanese
On December 7th, we launched our new Japanese voice search system (音声検索), which has been available for various flavors of English since last year and for Mandarin Chinese for the past two months. The initial Japanese system works on the Android platform and also through the Google Mobile App on the iPhone as announced in a Japanese blog and a general explanation on how to get started. For developers who want to make use of the speech recognition backend for their own Android applications there is a public API (recognizer intent API) described here.
Although speech recognition has had a long history in Japan, creating a system that can handle a problem as difficult as voice search is still a considerable challenge. Today, most speech recognition systems are large statistical systems that must learn two models from sets of examples, an acoustic model and a language model. The acoustic model represents (statistically) the fundamental sounds of the language, and the language model statistically represents the words, phrases, and sentences of the language. The acoustic model for Japanese voice search was trained using a large amount of recorded Japanese speech, with the associated transcriptions of the words spoken. The language model for Japanese voice search was trained on Japanese search queries.
While speech recognition systems are surprisingly similar across different languages, there are some problems that are more specific to Japanese. Some of the challenges we faced while developing Japanese voice search included:
- Spaces in Japanese text
As we looked at some popular search queries in Japan we saw that Japanese often doesn't have spaces but sometimes it does. For example, if a user searches for Ramen noodles near Tokyo station they will often type: "東京駅 ラーメン" with a space in between Tokyo station and Ramen -- therefore, we would like to display it in this way as well. Getting the spaces right is difficult and we continue working to improve it. - Japanese word boundaries
Word boundaries in Japanese are often not clear and subject to interpretation as most of the time there are not spaces between words. This also makes the definition of the vocabulary (the words that can be recognized theoretically) extremely large. We deal with this problem by finding likely word boundaries using a statistical system which also helps us limit the vocabulary. - Japanese text is written in 4 different writing systems
Japanese text as written today uses Kanji, Hiragana, Katakana & Romaji, often mixed in the same sentence and sometimes in the same word, depending on the definition of a word. Try these example queries to see some interesting cases: "価格.com", "マーボー豆腐", "東京都渋谷区桜丘町26-1". We try to display the output in a way that is most user-friendly, which often means to display it as you would write it down. - Japanese has lots of basic characters and many have several pronunciations depending on context
To be able to recognize a word you need to know its pronunciation. Western languages in general use only ASCII or a slightly extended set of characters which is relatively small (less than 100 total in most cases). For Japanese the number of basic characters is the union of all basic characters from the four writing systems mentioned above, which is several thousands in total. Finding the correct pronunciations for all words in the very large voice search vocabulary is difficult and is often done using a combination of human effort and automatic statistical systems. This is even more difficult in the Japanese case as the number of basic characters is higher and there are a vast number of exceptions, for example consider the case of: "一人" (hitori) versus "一人前" (ichininmae). Although the phrases look very similar they have completely different pronunciations. - Encoding issues
Japanese characters can be written in many encoding systems including UTF-8, Shift_JIS, EUC-JP and others. While at Google we try to use exclusively UTF-8 there are still interesting edge cases to deal with. For example some characters exist in different forms in the same encoding system. Compare for example "カナ" and "カナ" -- they both say "kana" and mean the exact same thing, the first in full-width and the second in half-width. There are numerous similar cases like this in Japanese that make normalization of the text data more difficult. - Every speaker sounds different
People speak in different styles, slow or fast, with an accent or without, have lower or higher pitched voices, etc. To make it work for all these different conditions we trained our system on data from many different sources to capture as many conditions as possible.
Friday, December 11, 2009
Research Areas of Interest - Multimedia
Recently, Google's research groups reviewed over 140 grant proposals across sixteen different research areas. During this process, we identified a number of strategic research topics. These topics represent critical areas of research for Google in collaboration with our university partners.
We'll be examining several of these topics in future posts but we'd like to begin by raising some of the research challenges we face in our multimedia endeavors:
- Large scale annotation: How can we learn from large, noisy sets of image/video data to automatically get human-level accurate models for label annotation?
The images and videos that are available on the web provide massive data sets. We have some very noisy labels on that set, in terms of possible content. We have labels based on popularity of an item when considered for a particular search, on anchor text and other context, and on labels given to other content that is often associated with each item. The challenge is to make use of the sheer volume of available data to improve our recognition models and to carry appearance models from one media type to another. Further, we must be able to handle the variability in appearance and in the labels themselves. - Image/Audio/Video Representation: How can we improve our understanding of low level representations of images that goes beyond bag of words modeling?
Much of the current work in labeling and retrieval is based on fairly simple local descriptions of the content, putting the emphasis on classifier learning from combinations of simple models. While this classifier approach has been useful, we should also examine the basic features that we are using, to see if we can better characterize the content. Providing better inputs into our learning algorithms should reduce the size of the space over which we need to search. Possible examples include shape modeling in images, better texture/color models, and descriptions of soft segmentations of regions. - Localization of image-/video-level labels to spatial/temporal portions of the content: Can we automatically associate image and video labels with specific portions of the content?
The most obvious examples in this area are labels like "dog" and "explosion". However, can we also localize more complex concepts like "waves" or "suspense"? Alternately, can we automatically distinguish between labels, based on how well we are able to localize them to a particular place or time within the content? - Large scale matching / Hashing: Can we identify matching techniques to deal with large datasets?
We need image, video, and audio matching techniques that can effectively deal with large datasets, embedded in high-dimensional descriptor spaces, in sub-linear time. Of special interest are methods that can efficiently handle a wide range of recall/precision needs without massive increases in the data-structure sizes that are used.
We expect these questions to keep us busy for some time.
Wednesday, December 9, 2009
Machine Learning with Quantum Algorithms
Many Google services we offer depend on sophisticated artificial intelligence technologies such as machine learning or pattern recognition. If one takes a closer look at such capabilities one realizes that they often require the solution of what mathematicians call hard combinatorial optimization problems. It turns out that solving the hardest of such problems requires server farms so large that they can never be built.
A new type of machine, a so-called quantum computer, can help here. Quantum computers take advantage of the laws of quantum physics to provide new computational capabilities. While quantum mechanics has been foundational to the theories of physics for about a hundred years the picture of reality it paints remains enigmatic. This is largely because at the scale of our every day experience quantum effects are vanishingly small and can usually not be observed directly. Consequently, quantum computers astonish us with their abilities. Let’s take unstructured search as an example. Assume I hide a ball in a cabinet with a million drawers. How many drawers do you have to open to find the ball? Sometimes you may get lucky and find the ball in the first few drawers but at other times you have to inspect almost all of them. So on average it will take you 500,000 peeks to find the ball. Now a quantum computer can perform such a search looking only into 1000 drawers. This mind boggling feat is known as Grover’s algorithm.
Over the past three years a team at Google has studied how problems such as recognizing an object in an image or learning to make an optimal decision based on example data can be made amenable to solution by quantum algorithms. The algorithms we employ are the quantum adiabatic algorithms discovered by Edward Farhi and collaborators at MIT. These algorithms promise to find higher quality solutions for optimization problems than obtainable with classical solvers.
On the hardware side we are collaborating with D-Wave in Vancouver, Canada. D-Wave develops processors that realize the adiabatic quantum algorithm by magnetically coupling superconducting loops called rf-squid flux qubits. This design realizes what is known as the Ising model which represents the simplest model for an interacting many-body system and it can be manufactured using proven chip fabrication methods. Unfortunately, it is not easy to demonstrate that a multi-qubit system such as the D-Wave chip indeed exhibits the desired quantum behavior and experimental physicists from various institutions are still in the process of characterizing the chip.

Layout of the qubits in the C4 Chimera chip employed to train the car detector. The irregular graph structure results from the fabrication process not yet rendering all qubits functional.
Today, at the Neural Information Processing Systems conference (NIPS 2009), we show the progress we have made. We demonstrate a detector that has learned to spot cars by looking at example pictures. It was trained with adiabatic quantum optimization using a D-Wave C4 Chimera chip. There are still many open questions but in our experiments we observed that this detector performs better than those we had trained using classical solvers running on the computers we have in our data centers today. Besides progress in engineering synthetic intelligence we hope that improved mastery of quantum computing will also increase our appreciation for the structure of reality as described by the laws of quantum physics.
The theory paper on which the demonstration is based can be found on the arXiv and a report describing the details of the implementation is here.
Tuesday, December 8, 2009
Windows 7: Understanding Network Administration and Configuration
Windows 7: Understanding Network Administration and Configuration
Important differences and improvements between Windows Vista and the new Windows 7 OS when it comes to configuring networking. | |

|
Introduction
At first glance there aren’t too many differences between configuring Windows 7 networking and configuring Windows Vista networking. However, there are important differences once you start using Windows 7. Let us find them out. Navigation – getting to Windows 7 Network Configuration
Navigation – getting to Windows 7 Network Configuration
How do you get to Windows 7 Network configuration? Just go to the Start Menu, then to Control Panel, and click on Network and Internet. You also can get to your network configuration, using the same navigation path in Windows Vista. However, when you get to the Network and Internet settings in Windows Vista, you will see a lot more options. Let us compare by starting with the Windows 7 Network and Internet window (shown in Figure 1, below).
Figure 1: Windows 7 Network and Internet Configuration
As you can see this new Windows 7 configuration window offers you a few new choices and a few old choices but, overall, not a lot of choices to choose from. We are used to seeing both the Network and Sharing Center and the Internet Options but the HomeGroup is new. I will come back to HomeGroup and the new and improved Network and Sharing Center in Windows 7, below.
Now let us compare what we saw in Windows 7 to the Network and Internet configuration in Windows Vista, shown in Figure 2, below:

Figure 2: Windows Vista Network and Internet Configuration
The first thing you notice is that there are tons of options to choose from in Vista. However, I do not think that this is such a good thing as some of these seem much less important than others. For example, I don’t think that the Windows Firewall or Offline Files deserve their own section here (these are removed in Windows 7).
Windows 7 Network and Sharing Center
99% of the time, in Windows 7 or Vista, to configure networking, you are going to click on the Network and Sharing Center. It offers the most functionality and the most common tasks that a Windows Vista or 7 Administrator would perform. So, let us look at how the Network and Sharing Center differs between these two operating systems.First, here is the Network and Sharing Center from Windows Vista that most of us are familiar with:

Figure 3: Windows Vista Network and Sharing Center
Now, let us compare that to Windows 7’s Network and Sharing Center, below in Figure 4.

Figure 4: Windows 7 Network and Sharing Center
One of the big differences is caused by these two computers being different. The Vista computer has many more network adaptors as compared to the Windows 7 computer. That aside, as you can see, the Windows 7 computer actually has many fewer options than the Vista computer. Options have been removed from the left navigation and the Sharing and Discovery options have been removed from the main window. These options have just been moved to other sections.
The Network and Sharing options have been moved to the Choose homegroup and sharing options window (which we will look at in a minute). The left navigation options shown on the Vista computer have just been moved to the level above this, Network and Internet.
What I like about the new Windows 7 Network and Sharing center is that the less related options have been moved off to reduce the clutter on the page. There are two things that I do not care for, concerning the changes with the Network and Sharing center:
- Why did they remove the Sharing and Discovery options from this page? I mean, it is not that what the Network and Sharing center should have – sharing and discovery options?
- Also, I have never cared for how in Vista or Windows 7 there are no technical networking details on the network and sharing center page. I should be able to see if I have an IP address here. I should be able to see if it is 169.254.xxx.xxx automatic (useless) IP address or if it is a real IP address. I would think that they would have added / improved this in Windows 7.
What about Windows 7 Homegroup?
Above, I mentioned Windows 7 homegroup. What is this? Well, this is new in Windows 7. A homegroup is a simple way to link computers on your home network together so that they can share pictures, music, videos, documents, and printers. There is just a single password that is used to access the homegroup, making creating it and connecting to it easy.If you click on Choose Homegroup and Sharing Options from the Network and Sharing Center in Windows 7, you will see this window (assuming your network location is not Home):

Figure 5: Homegroup and sharing options in Windows 7
If you change your network location to Home, you will see the option to create a homegroup. Or if you come to the Choose Homegroup and sharing options page when your network location is set to home, then you can choose Create now and create your new homegroup.

Figure 6: Creating a Windows 7 Homegroup
You will be able to select what you want to share in the homegroup.

Figure 7: Viewing the Windows 7 Password to connect to the homegroup
And you will be given a single password, used on other computers, to connect to the homegroup.
When you are done, the Homegroup and Sharing center will look something like this:

Figure 8: Windows 7 Homegroup configured
Fix a network problem
My favorite change to Windows 7 networking is the update to Vista’s diagnose and repair. In Windows 7 if you want to get assistance fixing a network issue, you just click Fix a network problem. Sound simple and clear, right? That’s what I like about it.From Windows 7 Network and Sharing, if you click Fix a Network Problem, you get this window, asking you want you want to fix:

Figure 9: Fixing a Network Problem
Windows 7 will go through and attempt to fix any network issues that you select. It will even ask you if you want to fix it as a Windows Administrator. Here is what fixing a homegroup looks like:

Figure 10: Fixing a network problem
Conclusion
Overall, I like the changes to Windows 7 networking GUI administration tools. The simplification of the interface is nice, as are the “fix a network problem tool” and the new homegroup features. I encourage you to take a look at these Windows 7 networking changes yourself.Celebrating Computer Science Education Week
[cross-posted with the Official Google Blog]
Today kicks off the nation’s first Computer Science Education Week. The goal of this week is to encourage students to learn about the discipline that powers the computers, applications and technology they use everyday. Computer Science Education Week emphasizes that our society's aspirations will be met by individuals who have an increasingly deep understanding of computer technology.
We've been thinking about ways that Google could help with computer science education for several years. After all, our search engine has been used in education since its inception — how many essays, research papers and theses begin with a Google search? Today, we'd like to summarize some of what we've been doing at Google to advance CS education. Our efforts focus on four strategic areas, with an emphasis on computing in core curriculum.
Use of Google tools to support teaching and learning
Having a web-based shared document, spreadsheet or presentation that students in a group or class can all view and edit online has had an enormous impact on collaboration in education. So we provide a free suite of our communication & collaboration applications designed especially for schools and universities. We also used our tools and infrastructure to build and support a community of teachers who have developed classroom content and activities around these applications.
Increasing the access to and quality of Computer Science curriculum
We have many people at Google who know about all areas of computer science, many with backgrounds and experience in education. With this deep base of computer science knowledge, we developed Google Code University to help faculty update their undergraduate computer science curriculum, and the Summer of Code, which gives students the opportunity to develop programs for various open source software projects.
Integrating computing curriculum across K-12 core subjects
A group of Google engineers and K-12 "teaching fellows" is working on building and testing models of curriculum to encourage innovation. These curriculum models revolve around "computational thinking", a problem-solving technique that draws on the thinking and analysis skills that computer scientists use everyday. Our goal is to integrate computational thinking across subject areas in K-12 by connecting these skills, which are already a part of core curriculum, more explicitly to computer science. We're also taking this a step further by integrating simple programming concepts in appropriate areas of core K-12 curriculum, such as algebra. Our hope is that by making computer science more visible and showing its connection to every subject area, students will experience the full power and utility of technology in areas of interest to them. Integrating CS into other subjects will also have the key added benefit of leveling the playing field, so that many more students will have the opportunity to gain a deeper understanding of computing.
Supporting organizations and individuals through community outreach
We've also worked for years with teachers and nonprofits to build early interest in the Science, Technology, Engineering and Math (STEM) fields. Besides providing financial support and sponsorship for many external organizations, we've developed a number of scholarship and intern programs to increase the number of women and underrepresented minorities in STEM and computer science. In addition to these formal programs, every day Googlers all over the world organize visits with students at nearby schools and community centers to teach, present workshops and tech talks, and to share their personal stories on how they became computer scientists and engineers.
We're absolutely delighted to be a co-sponsor of the first Computer Science Education Week. As a company, we've benefited so much from advances in computer science and the creativity of computer scientists. We also know that the next great innovators in computer science are out there, ready to be inspired to create technologies that change our world and benefit our society. We urge our children, parents, teachers and educational institutions to pay more attention to this critical field, and we will continue to do our share.
Join us for the 2010 Google GRAD CS Forum!
[cross-posted with the Google Student Blog]
As part of Google’s ongoing commitment to encouraging students of underrepresented backgrounds in technology to pursue graduate study, we are pleased to host the first annual 2010 Google Graduate Researchers in Academia of Diverse backgrounds (GRAD) CS Forum. This forum will bring together students who are historically underrepresented in the field to connect with one another and with Google.
Up to 75 computer scientists will be invited to an all-expenses paid forum that will run Thursday evening through Saturday afternoon on January 21–23 at Google’s headquarters in Mountain View, CA.
The Google GRAD CS Forum will include technical talks from established researchers – both from Google and universities – and a unique occasion to build and strengthen networks with other emerging researchers. Students will also enjoy tours of the Googleplex, have the opportunity to meet with Google engineers in their focus areas, and have fun exploring the San Francisco Bay Area.
Eligibility Requirements
Applicants must:
- be a computer science (or related technical discipline) graduate student currently enrolled in a Masters or PhD program at a university in North America
- demonstrate academic excellence and leadership in the computing field
- maintain a cumulative GPA of at least 3.3 on a 4.0 scale or 4.3 on a 5.0 scale or equivalent in their current program
Selection Process
Google engineers will select up to 75 attendees based on each applicant’s academic and technical achievements. Evidence of academic achievement and leadership experience should be evident from the resume.
How to Apply
Complete the online application and submit all required documents online. First-time users will be required to register and create an account. Please note that recommendation letters are not required.
Application Deadline: December 12, 2009
Apply now at www.google.com/jobs/students/gradforum.
Note: letters of recommendation are not required
Saturday, December 5, 2009
Automatic Captioning in YouTube
On November 19, we launched our new automatic captioning and automatic alignment feature for YouTube. These features significantly reduce the effort it takes to create captions for videos on YouTube.
With YouTube expanding its index at a breakneck speed of about 20 hours of new material uploaded each minute, access to this vast body of video material becomes increasingly challenging. This is particularly true for people with hearing disabilities. A 2005 US census showed that 7.8 million people (or about 3 percent of the US population) have difficulty hearing a normal conversation, with 1 million unable to hear at all. Hence, increased accesibility by adding captions to YouTube videos makes the corpus available to a much larger audience.
In addition to expanded accessibility for those with hearing disabilities, the combination of captions with machine translation expands YouTube accessibility across the globe. If a caption track is available, it can be translated automatically in any of the 51 currently available languages. As a result, video content otherwise not accessible due to a language barrier can now be understood by a significantly larger user population.
Although captions are available in YouTube for hundreds of thousands of videos, it remains only a fraction of the the available corpus. Furthermore, only a tiny fraction of the avalanche of new video material getting uploaded is captioned. One reason for this lack of coverage is the effort it takes for a video uploader to generate captions. And this is where our new auto captioning and auto alignment features can benefit our uploaders. Auto-captioning uses automatic speech recognition technology to produce machine generated captions. Auto-alignment requires only a transcript--the uploader no longer has to sync that text with the video stream. To more concisely illustrate the use of these features, check out our help center article or this short video:
Modern-day speech recognition systems are big statistical machines trained on large sets of data. They do the best job recognizing speech in domains similar to their training data. Both the auto captioning and the auto alignment features use the speech recognition infrastructure that underlies Google Voice and Voice Search, but trained on different data. As an intial installment, for YouTube we use models trained on publicly available English broadcast news data. As a result, for now, the new features only work well on English material that is similar in style (i.e. an individual speaker who is speaking clearly).
The auto alignment features is available for all new video uploads, however the scope is limited to English material. The auto captioning feature is initially rolled out to a set of educational partners only. Although this is very limited in scope, the early launch makes the results of the system available to the viewers of this material instantly and it allows us to gauge early feedback which can aid in improving the features. We will release automatic captions more widely as quickly as possible.
Over time, we will work on improving the quality as well as the coverage of these features. Expansion will take place along two axes: additional languages will be made available and within each language we will cover much broader domains (beyond just broadcast news-like material). Since the content available in YouTube is so varied, it is difficult to set a timeline for this expansion. Automatic speech recognition remains challenging, in particular for the varied types of speech and background sounds and noise we see in the YouTube corpus. Therefore, to reach a high level of quality, we need to make advances in core technology. Although this will take time, we are committed to making that happen and to providing the larger community with the benefits of those developments.
Tuesday, December 1, 2009
Four Googlers elected ACM Fellows
I'm excited to share that the Association for Computing Machinery (ACM) has just announced that four Googlers have been elected ACM Fellows in its class of 2009. Jeff Dean, Tom Dean, Urs Hoelzle and Yossi Matias were chosen for their achievements in computer science and information technology and for their significant contributions to the mission of the ACM. Here at Google, we take great pride in having a tremendously talented workforce, and the talent of our team is exemplified by the addition of Jeff, Tom, Urs and Yossi to the six other ACM Fellows already at Google.
All of these Googlers are being recognized for successes both inside and outside Google. Urs' and Jeff's achievements are most directly related to innovations made while at Google, specifically in our large data centers and in harnessing their inherent parallel computation and vast storage. Tom and Yossi, on the other hand, were elected more for work done prior to Google — respectively, on how to use prediction in planning, control, and decision-making where there is both uncertainty and time constraints, and on theoretically and practically interesting techniques for analyzing and managing large data sets and data streams.
We at Google congratulate our colleagues. They serve as an inspiration to us and to our colleagues in computer science globally and remind us to continue to push the limits of computing, which has enormous benefits to our field and to society at large.
You can read more about Jeff, Tom, Urs and Yossi's achievements and the reasons for this recognition by the ACM below. The citations are the official ones from the ACM.
Jeff Dean, Google Fellow
For contributions to the science and engineering of large-scale distributed computer systems
Dr. Jeff Dean has made great contributions to the programming and use of loosely-coupled multiprocessing systems and cloud computing. Jeff is probably best known for his work (with Sanjay Ghemawat) on the parallel/distribution computing infrastructure called MapReduce, a tremendously influential programming model for batch jobs on loosely coupled multiprocessing systems. Working with others, Jeff has also been a leading contributor to many other Google systems: the BigTable record storage system, which reliably stores diverse record data records (via portioning and replication) in vast quantities, at least two production real-time indexing systems, and several versions of Google's web serving system. The breadth of Jeff's work is quite amazing: At Digital, he co-developed a leading Java compiler and the Continuous Profiling Infrastructure (DCPI). Beyond this core systems work, Jeff has had exceedingly diverse additional activities; for example, he co-designed Google's first ads serving system, made significant quality improvements to the search system, and even has been involved in user-visible efforts such as the first production version of Google News and the production implementation of Google's machine translation system. Despite his primary accomplishments as a designer and implementer of innovative systems that solve hard problems in a practical way, Jeff also has over 20 publications in peer-reviewed publications, more than 25 patents, and is one of Google's most sought-after public speakers.
Thomas L. Dean, Staff Research Scientist
For the development of dynamic Bayes networks and anytime algorithms
Dr. Tom Dean is known in AI for his work on the role of prediction in planning, control and decision-making where uncertainty and the limited time available for deliberation complicate the problem, particularly his work on temporal graphical models and their application in solving robotics and decision-support problems. His temporal Bayesian networks, later called dynamic Bayes networks, made it possible to factor very large state spaces and their corresponding transition probabilities into compact representations, using the tools and theory of graphical models. He was the first to apply factored Markov decision processes to robotics and, in particular, to the problem of simultaneous localization and map building (SLAM). Faced with the need to solve what were essentially intractable problems in real-time, Dean coined the name "anytime algorithm" to describe a class of approximate inference algorithms and the associated (meta) decision problem of deliberation scheduling to address the challenges of bounded-time decision making. These have been applied to large-scale problems at NASA, Honeywell, and elsewhere. At Google, Tom has worked on extracting stable spatiotemporal features from video and developed new, improved features for video understanding, categorization and ranking. During his twenty-year career as a professor at Brown University, he published four books and over 100 technical articles, while serving terms as department chair, acting vice president for computing and information services, and deputy provost.
Urs Hoelzle, Senior Vice President of Engineering
For the design, engineering and operation of large scale cloud computing systems
Dr. Urs Hoelzle has made significant contributions to the literature, theory, and practice in many areas of computer science. His publications are found in areas such as compilers, software and hardware architecture, dynamic dispatch in processing systems, software engineering and garbage collection. Much of this work took place during his time at Stanford and later at UC Santa Barbara as a member of the faculty. Urs' most significant contribution to computer science and its application is found in his work and leadership at Google. Since 1999 he has had responsibility for leading engineering and operations of one of the largest systems of data centers and networks on the planet. That it has been able to scale up to meet the demands of more than a billion users during the past 10 years is an indication of his leadership ability and remarkable design talent. Urs works best in collaborative environments, as evidenced by his publications and in his work at Google. While it would be incorrect to credit Urs alone for the success of the Google computing and communications infrastructure, his ability to lead a large number of contributors to a coherent and scalable result is strong evidence of his qualification for advancement to ACM Fellow. The philosophy behind Google's system of clustered, distributed computing systems reflects a powerful pragmatic: assume things will break; use replication, not gold-plating, for resilience; reduce power requirements where ever possible; create general platforms that can be harnessed in myriad ways; eschew specialization except where vitally necessary (e.g., no commercial products fit the requirement). Much of this perspective can be attributed to Urs Hoelzle.
Yossi Matias, Director of R&D Center in Israel
For contributions to the analysis of large data sets and data streams
Dr. Yossi Matias has made significant contributions to the analysis of large data sets and data streams. He pioneered (with Phillip Gibbons) a new research direction into the study of small-space (probabilistic) “synopses” of large data sets, motivating their study and making key contributions in this area. Yossi’s 1996 paper (with Noga Alon and Mario Szegedy) won the 2005 Gödel Prize, the top ACM prize in Theoretical Computer Science, awarded annually. The award citation describes the paper as having “laid the foundations of the analysis of data streams using limited memory." Further, “It demonstrated the design of small randomized linear projections, subsequently referred to as ‘sketches,’ that summarize large amounts of data and allow quantities of interest to be approximated to user-specified precision.” Additionally, Yossi has made several key contributions to lossless data compression of large data sets, including a “flexible parsing” technique that improves upon the Lempel-Ziv dictionary-based compression algorithm, and novel compression schemes for images and for network packets. Large scale data analysis requires effective use of multi-core processors. For example, his JACM paper (with Guy Blelloch and Phillip Gibbons) provided the first provably memory- and cache-efficient thread scheduler for fine-grained parallelism. In addition to his academic and scientific impact, Yossi has been heavily involved in the high tech industry and in technology and product development, pushing the commercial frontiers for analyzing large data sets and data streams. He is also the inventor on 23 U.S. patents. Yossi joined Google in 2006 to establish the Tel-Aviv R&D Center, and to be responsible for its strategy and operation. Yossi has overall responsibility for Google R&D and technology innovation in Israel.
Tuesday, November 24, 2009
Explore Images with Google Image Swirl
Earlier this week, we announced the Labs launch of Google Image Swirl, an experimental search tool that organizes image-search results. We hope to take this opportunity to explain some of the research underlying this feature, and why it is an important area of focus for computer vision research at Google.
As the Web becomes more "visual," it is important for Google to go beyond traditional text and hyperlink analysis to unlock the information stored in the image pixels. If our search algorithms can understand the content of images and organize search results accordingly, we can provide users with a more engaging and useful image-search experience.
Google Image Swirl represents a concrete step towards reaching that goal. It looks at the pixel values of the top search results and organizes and presents them in visually distinctive groups. For example, in ambiguous queries such as "jaguar," Image Swirl separates the top search results into categories such as jaguar the animal and jaguar the brand of car. The top-level groups are further divided into collections of subgroups, allowing users to explore a broad set of visual concepts associated with the query, such as the front view of a Jaguar car or Eiffel Tower at night or from a distance. This is a distinct departure from the way images are ranked by the Google Similar Images, which excels at finding images very visually similar to the query image.
No matter how much work goes into engineering image and text features to represent the content of images, there will always be errors and inconsistencies. Sometimes two images share many visual or text features, but have little real-world connection. In other cases, objects that look similar to the human eye may appear drastically different to computer vision algorithms. Most difficult of all, the system has to work at Web Scale -- it must cover a large fraction of query traffic, and handle ambiguities and inconsistencies in the quality of information extracted from Web images.
In Google Image Swirl, we address this set of challenges by organizing all available information about an image set into a pairwise similarity graph, and applying novel graph-analysis algorithms to discover higher-order similarity and category information from this graph. Given the high dimensionality of image features and the noise in the data, it can be difficult to train a monolithic categorization engine that can generalize across all queries. In contrast, image similarities need only be defined for similar enough objects and trained with limited sets of data. Also, invariance to certain transformations or typical intra-class variation can be built into the perceptual similarity function. Different features or similarity functions may be selected, or learned, for different types of queries or image contents. Given a robust set of similarity functions, one can generate a graph (nodes are images and edges are similarity values) and apply graph analysis algorithms to infer similarities and categorical relationships that are not immediately obvious. In this work, we combined multiple sources of similarity such as those used in Google Similar Images, landmark recognition, Picasa's face recognition, anchor text similarity, and category-instance relationships between keywords similar to that in WordNet. It is a continuation of our prior effort [paper] to rank images based on visual similarity.
As with any practical application of computer vision techniques, there are a number of ad hoc details which are critical to the success of the system but are scientifically less interesting. One important direction of our future work will be to generalize some of the heuristics present in the system to make them more robust, while at the same time making the algorithm easier to analyze and evaluate against existing state-of-the-art methods. We hope that this work will lead to further research in the area of content-based image organization and look forward to your feedback.
UPDATE: Due to the shutdown of Google Labs, this service is longer active.
Monday, November 23, 2009
Cara Mudah dalam Mengaktifkan Print Spooler
ditulis oleh Basyarah
 Dalam setiap kegiatan, manusia mengharapkan kemudahan dalam melaksanakannya. Salah satu kegiatan tersebut adalah membuat dokumen. Bayangkan pada saat zaman mesin ketik, salah ketik satu huruf saja harus mengganti kertas, namun setelah adanya komputer semuanya terasa lebih mudah.
Dalam setiap kegiatan, manusia mengharapkan kemudahan dalam melaksanakannya. Salah satu kegiatan tersebut adalah membuat dokumen. Bayangkan pada saat zaman mesin ketik, salah ketik satu huruf saja harus mengganti kertas, namun setelah adanya komputer semuanya terasa lebih mudah.Terkait dengan dokumen, salah satu alat untuk mencetak atau printer sudah sangat dibutuhkan, dimana sudah berbagai macam jenis printer seperti laser jet, bubble jet, dot matrix, dan jenis lainnya. Namun dalam pelaksanaannya dibalik kemudahan itu selalu ada kesulitan yang dapat kita temukan. Misalnya tidak bisa mencetak dokumen. Banyak masalah yang harus di analisa terlebih dahulu, dan tidak instant dapat menebak kesalahannya.
Nah, dalam tulisan ini saya membahas salah satu masalah kenapa driver printer tidak dapat di install. Sebetulnya caranya mudah namun jika belum menemukan solusinya akan terasa lebih sulit. Pada saat anda meng-install driver printer namun tidak bisa, dimana terdapat pesan error “Operation could not be completed. The print spooler service is not running” maka terdapat permasalahan pada service print spooler.
Apa itu print spooler?
Print spooler adalah suatu service di windows yang berfungsi untuk memuat file atau dokumen ke memory untuk di cetak. Jika service ini tidak dalam kondisi aktif maka proses mencetak tidak dapat dilaksanakan, termasuk menginstall printer driver. Sekarang anda mungkin mempunyai pertanyaan seperti ini “bagaimana cara mengaktifkan print spooler ini?” sebetunya caranya sangat mudah yaitu:
- buka control panel >> Administrative Tools >> services
- cari print spooler kemudian klik dua kali
- set startup type ke “Automatic”
- klik tombol “Start”
Maksunya apa ya startup type itu?
Untuk pemula memang terdapat istilah-istilah komputer yang membingungkan, tapi ini memang harus diketahui. Kamu dapat melihat tulisan saya mengenai startup ini.
Saturday, November 14, 2009
The 50th Symposium on Foundations of Computer Science (FOCS)
The 50th Annual Symposium on Foundations of Computer Science (FOCS) was held a couple of weeks ago in Atlanta. This conference (along with STOC and SODA) is one of the the major venues for recent advances in algorithm design and computational complexity. Computation is now a major ingredient of almost any field of science, without which many of the recent achievements would not have happened (e.g., Human Genome decoding). As the 50th anniversary of FOCS, this event was a landmark in the history of foundations of computer science. Below, we give a quick report of some highlights from this event and our research contribution:
- In a special one-day workshop before the conference, four pioneer researchers of theoretical computer science talked about historical, contemporary, and future research directions. Richard Karp gave an interesting survey on "Great Algorithms," where he discussed algorithms such as the simplex method for linear programming and fast matrix multiplication; he gave examples of algorithms with high impact on our daily lives, as well as algorithms that changed our way of thinking about computation. As an example of an algorithm with great impact on our lives, he gave the PageRank algorithm designed by Larry and Sergey at Google. Mihalis Yannakakis discussed the recent impact of studying game theory and equilibria from a computational perspective and discussed the relationships between the complexity classes PLS, FIXP, and PPAD. In particular he discussed completeness of computing pure and mixed Nash equilibria for PLS, and for FIXP and PPAD respectively. Noga Alon gave a technical talk about efficient routing on expander graphs, and presented a clever combinatorial algorithm to route demand between multiple pairs of nodes in an online fashion. Finally, Manuel Blum gave an entertaining and mind-stimulating talk about the potential contribution of computer science to the study of human consciousness, educating the community on the notion of "Global Workspace Theory."
- The conference program included papers in areas related to algorithm and data structure design, approximation and optimization, computational complexity, learning theory, cryptography, quantum computing, and computational economics. The best student paper awards went to Alexander Shrstov and Jonah Sherman for their papers "The intersection of two halfspaces has high threshold degree" and "Breaking the multicommodity flow barrier for O(sqrt(log n))-approximations to sparsest cut." The program included many interesting results like the polynomial-time smoothed analysis of the k-means clustering algorithm (by David Arthur, Bodo Manthey and Heiko Roeglin), and a stronger version of Azuma's concentration inequality used to show optimal bin-packing bounds (by Ravi Kannan). The former paper studies a variant of the well-known k-means algorithm that works well in practice, but whose worst-case running time can be exponential. By analyzing this algorithm in the smoothed analysis framework, the paper gives a new explanation for the success of the k-means algorithm in practice.
- We presented our recent result about online stochastic matching in which we improve the approximation factor of computing the maximum cardinality matching in an online stochastic setting. The original motivation for this work is online ad allocation which was discussed in a previous blog post. In this algorithm, using our prior on the input (or our historical stochastic information), we compute two disjoint solutions to an instance that we expect to happen; then online, we try one solution first, and if it fails, we try the the other solution. The algorithm is inspired by the idea of "power of two choices," which has proved useful in online load balancing and congestion control. Using this method, we improve the worst-case guarantee of the online algorithm past the notorious barrier of 1-1/e. We hope that employing this idea and our technique for online stochastic optimization will find other applications in related stochastic resource allocation problems.
Friday, November 13, 2009
A 2x Faster Web
Cross-posted with the Chromium Blog.
Today we'd like to share with the web community information about SPDY, pronounced "SPeeDY", an early-stage research project that is part of our effort to make the web faster. SPDY is at its core an application-layer protocol for transporting content over the web. It is designed specifically for minimizing latency through features such as multiplexed streams, request prioritization and HTTP header compression.
We started working on SPDY while exploring ways to optimize the way browsers and servers communicate. Today, web clients and servers speak HTTP. HTTP is an elegantly simple protocol that emerged as a web standard in 1996 after a series of experiments. HTTP has served the web incredibly well. We want to continue building on the web's tradition of experimentation and optimization, to further support the evolution of websites and browsers. So over the last few months, a few of us here at Google have been experimenting with new ways for web browsers and servers to speak to each other, resulting in a prototype web server and Google Chrome client with SPDY support.
So far we have only tested SPDY in lab conditions. The initial results are very encouraging: when we download the top 25 websites over simulated home network connections, we see a significant improvement in performance - pages loaded up to 55% faster. There is still a lot of work we need to do to evaluate the performance of SPDY in real-world conditions. However, we believe that we have reached the stage where our small team could benefit from the active participation, feedback and assistance of the web community.
For those of you who would like to learn more and hopefully contribute to our experiment, we invite you to review our early stage documentation, look at our current code and provide feedback through the Chromium Google Group.
Tuesday, November 10, 2009
Earn Money By Reading SMS
SMS marketing is increasing very rapidly in India. Anybody can earn just by receiving advertisement through SMS. Now a days lots of companies are in this field but only few of them are authentic and really pays.
mGinger :This is one of the best and oldest Indian "paid to read SMS" website. This site is still operational and growing at a very fast pace.mGinger till now paid 1.32 crore to its users.

Get SMS ads of only those products that you want to buy.
Get ads at your convenience.
Get ads at your convenience.
Get number of ads as many as you want.
Save money through discount coupons and offers.
Save money through discount coupons and offers.
- Earn much more money by inviting family and friends
Get 20 paisa for every ad you receive
Get 10 paisa for every ad your friends receive
Get 5 paisa for every ad your friend's friends receive
Get 10 paisa for every ad your friends receive
Get 5 paisa for every ad your friend's friends receive
- Refer your friends and get Rs 2 on each valid referral:
Payment Proof :

CLICK HERE TO JOIN mGinger OR VISIT WWW.mGinger.COM

Tuesday, November 3, 2009
Google Search by Voice Learns Mandarin Chinese
Google Search by Voice was released more than one year ago as a feature of Google Mobile App, our downloadable application for smartphones. Its performance has been improving consistently and it now understands not only US English, but also UK, Australian, and Indian-English accents. However, this is far from Google's goal to find information and make it easily accessible in any language.
So, almost one year ago a team of researchers and engineers at Google's offices in Bangalore, Beijing, Mountain View, and New York decided we had to fix this problem. Our next question was, which should be our first language to address beyond English? We could have chosen many languages. The decision wasn't easy, but once we looked carefully at demographics and internet populations the choice was clear--we decided to work on Mandarin.
Mandarin is a fascinating language. Over this year we have learned about the differences between traditional and simplified Chinese, tonal characteristics in Chinese, pinyin representations of Chinese characters, sandhi rules, the different accents and languages in China, unicode representations of Chinese character sets...the list goes on and on. It has been a fascinating journey. The conclusion of all this work is today's launch of Mandarin Voice Search, as a part of Google Mobile App for Nokia s60 phones. Google Mobile App places a Google search widget on your Nokia phone's home screen, allowing you to quickly search by voice or by typing.


This is a first version of Mandarin search by voice and it is rough around the edges. It might not work very well if you have a strong southern Chinese accent for example, but we will continue working to improve it. The more you use it, the more it will improve, so please use it and send us your comments. And stay tuned for more languages. We know a lot of people speak neither English nor Mandarin!
To try Mandarin search by voice, download the new version of Google Mobile App on your Nokia S60 phone by visiting m.google.com from your phone's browser.
Wednesday, October 14, 2009
How to Convert Word to PDF and PDF to JPG
Universal Document Converter is the most complete solution for converting from DjVu to PDF or graphical files. The underlying basis of Universal Document Converter is the technology of virtual printing. As a result, exporting any document, table or presentation into PDF format is not any more complicated than printing on a desktop printer.
![]()
Convert DjVu to PDFThe first part of the article briefly compares the DjVu and PDF formats and tells why the PDF format is more suitable for publishing documents on the Internet than the DjVu format. Further on, a detailed description is given on how to convert DjVu to PDF.
About DjVuThe history of DjVu began in 1996. At that time, the company AT&T began work on the creation of a new format. The main task that was put before the developers was to create a technology of storing and sending scanned documents.
Currently the main benefit of the DjVu format is its small file size. According to the developers of the DjVu format, the size of a page from a color magazine saved in the DjVu file format does not exceed 70 KB, while a page from a black and white document is less than 40 KB. These results are significantly better than the average 500 KB required for saving documents of the abovementioned types in JPEG. What is more, scanned documents saved in DjVu often take up less space than if they were saved in PDF!
DjVu vs PDFUnfortunately, at the present time the DjVu format is popular only amongst enthusiasts. The majority of ordinary computer and Internet users have not even heard of it. However, the free Acrobat Reader program is installed on almost every computer. This is a weighty argument if you plan on placing your article on a site or send it to a scientific journal for publication.
Converting documents from DjVu into PDF simplifies access to it since after all, your readers don't have to install an additional viewer or plug-in for Internet Explorer. Plus, after converting scanned texts from DjVu to PDF or TIFF you can OCR them using software like ABBYY FineReader.
How to Convert DjVu to PDFDownload and install Universal Document Converter software onto your computer.
Install DjVu Browser Plugin for Internet Explorer from the Lizardtech site.
Open the DjVu file in Internet Explorer and press the Print button in the DjVu Browser Plugin toolbar:
![]()
Select Universal Document Converter from the list of printers and press the Properties button.
![]()
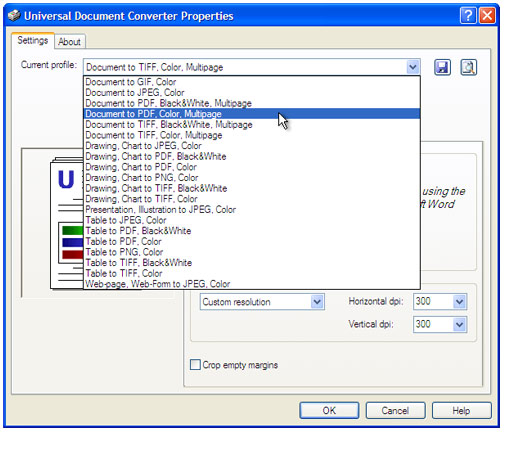
Select the Document to PDF, Color, Multipage profile in the Universal Document Converter Properties window and press OK.
![]()
Press OK in the Lizardtech plugin Print dialog to start converting. When the PDF file is ready, it will be saved to the
C:\UDC Output Files folder by default.
![]()
The converted document will then be opened in Adobe Acrobat or another viewer associated with PDF files on your computer.
![]() Frequently Asked QuestionsQ1: How to append several DjVu documents I have to one multipage PDF?
Frequently Asked QuestionsQ1: How to append several DjVu documents I have to one multipage PDF?
A1: Please open the Output tab in the Printing Preferences window. Select Append all pages to existing PDF file in Options drop down in bottom part of the window.
Q2: How do I keep 100% of the quality of the illustrated article I scanned to DjVu when I convert it to PDF?
A2: After selecting Document to PDF, Color, Multipage profile in the Universal Document Converter Properties window, please change Color Depth value to True Color (24 bpp). Then open the Page Setup tab and increase the Image Resolution value to 600 x 600 DPI.
Q3: I need to convert black and white scans from DjVu to PDF format. How can I reduce the size of the PDF file?
A3: Please use the Document to PDF, Black&White, Multipage profile in step 5 in the instructions above.

Convert DjVu to PDFThe first part of the article briefly compares the DjVu and PDF formats and tells why the PDF format is more suitable for publishing documents on the Internet than the DjVu format. Further on, a detailed description is given on how to convert DjVu to PDF.
About DjVuThe history of DjVu began in 1996. At that time, the company AT&T began work on the creation of a new format. The main task that was put before the developers was to create a technology of storing and sending scanned documents.
Currently the main benefit of the DjVu format is its small file size. According to the developers of the DjVu format, the size of a page from a color magazine saved in the DjVu file format does not exceed 70 KB, while a page from a black and white document is less than 40 KB. These results are significantly better than the average 500 KB required for saving documents of the abovementioned types in JPEG. What is more, scanned documents saved in DjVu often take up less space than if they were saved in PDF!
DjVu vs PDFUnfortunately, at the present time the DjVu format is popular only amongst enthusiasts. The majority of ordinary computer and Internet users have not even heard of it. However, the free Acrobat Reader program is installed on almost every computer. This is a weighty argument if you plan on placing your article on a site or send it to a scientific journal for publication.
Converting documents from DjVu into PDF simplifies access to it since after all, your readers don't have to install an additional viewer or plug-in for Internet Explorer. Plus, after converting scanned texts from DjVu to PDF or TIFF you can OCR them using software like ABBYY FineReader.
How to Convert DjVu to PDFDownload and install Universal Document Converter software onto your computer.
Install DjVu Browser Plugin for Internet Explorer from the Lizardtech site.
Open the DjVu file in Internet Explorer and press the Print button in the DjVu Browser Plugin toolbar:
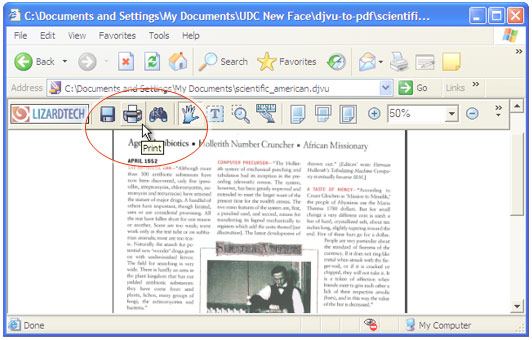
Select Universal Document Converter from the list of printers and press the Properties button.
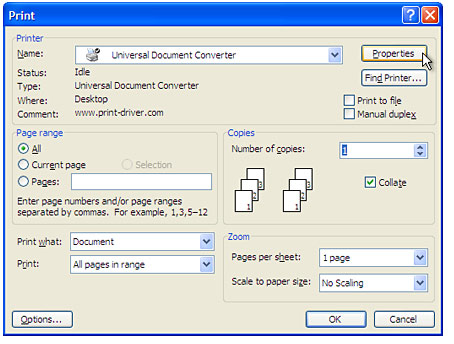
Select the Document to PDF, Color, Multipage profile in the Universal Document Converter Properties window and press OK.
Press OK in the Lizardtech plugin Print dialog to start converting. When the PDF file is ready, it will be saved to the
C:\UDC Output Files folder by default.
The converted document will then be opened in Adobe Acrobat or another viewer associated with PDF files on your computer.
A1: Please open the Output tab in the Printing Preferences window. Select Append all pages to existing PDF file in Options drop down in bottom part of the window.
Q2: How do I keep 100% of the quality of the illustrated article I scanned to DjVu when I convert it to PDF?
A2: After selecting Document to PDF, Color, Multipage profile in the Universal Document Converter Properties window, please change Color Depth value to True Color (24 bpp). Then open the Page Setup tab and increase the Image Resolution value to 600 x 600 DPI.
Q3: I need to convert black and white scans from DjVu to PDF format. How can I reduce the size of the PDF file?
A3: Please use the Document to PDF, Black&White, Multipage profile in step 5 in the instructions above.

Monday, October 5, 2009
How to downgrading Tube NOKIA 5800 with Software and USB cable
Before you do this, use at your own risk!
1. Download and install the requirement program in your PC (i recommend PC with OS Windows XP Service Pack 3)
JAF.1.98.62 (remove the * sign in the link)
This program already equipped with JAF Flasher box, but i recommend you use the newer version that you can get Here
2. Download the requirement software in this site -> Site
(emulator software that can emulate hardware flasher box)
3. Connect your Tube Nokia 5800 with PC using the USB Cable that you got in bundle.
4. Run emulator JAF box,
in step 1, choose Random Pkey Raskal SN
in step 2, choose JAF (main)
Click tab GO (Launched selected Exe)
5. Automatically, program JAF will start running.
choose tab BB5
in section flash setting, check the option what do you want, in this case downgrade in firmware
, so check downgrade option
uncheck normal box
in section operation, click TAB INF and CHK
in section phone mode, click tab ? (question mark)
6. After firmware and your phone mode recognized, click tab FLASH in section operation to do flashing
7. Wait till flashing process done, then you already success do flashing in your Tube Nokia 5800
1. Download and install the requirement program in your PC (i recommend PC with OS Windows XP Service Pack 3)
JAF.1.98.62 (remove the * sign in the link)
This program already equipped with JAF Flasher box, but i recommend you use the newer version that you can get Here
2. Download the requirement software in this site -> Site
(emulator software that can emulate hardware flasher box)
3. Connect your Tube Nokia 5800 with PC using the USB Cable that you got in bundle.
4. Run emulator JAF box,
in step 1, choose Random Pkey Raskal SN
in step 2, choose JAF (main)
Click tab GO (Launched selected Exe)
5. Automatically, program JAF will start running.
choose tab BB5
in section flash setting, check the option what do you want, in this case downgrade in firmware
, so check downgrade option
uncheck normal box
in section operation, click TAB INF and CHK
in section phone mode, click tab ? (question mark)
6. After firmware and your phone mode recognized, click tab FLASH in section operation to do flashing
7. Wait till flashing process done, then you already success do flashing in your Tube Nokia 5800
Saturday, October 3, 2009
BSNL free gprs trick. Unlimited downloads and surfing.
Hi, here is a trick for free unlimited gprs for BSNL..To activate it, just follow these steps:
1.you have to create two connections with any name like BSNL1 and BSNL2 with the following settings.
Access Point Name- "celloneportal"
Proxy Service Address- " 192.168.51.163 "
Proxy Port- "8080"
Security- "NORMAL"
No need to edit the other fields.
(If this settings is not working, you have to use the working settings in your region.)
- Now activate any of the two settings you created and try to access bsnl's home page using your phone's default browser. You will be able to access it.
- Now open another browser(eg: Opera) with the second settings keeping the default browser open. Now you will get "access denied" message.
- Keep both browsers working in background and open connection manager. In connection manager just disconnect the first connection.
- Now open the default browser from background. Now you can access all sites for free..
Thursday, October 1, 2009
NEW AIRTEL FREE GPRS TRICK SEPTEMBER 2009
Good news for Airtel users.Finally after a long period of time we found a 100% working Airtel Free GPRS Trick.This trick is successfully implemented on my Airtel mobile.
So I am going Share this trick :
To Activate Mobile office for airtel mobile Contact customer care for how to activate airtel mobile office on my mobile..!!
So I am going Share this trick :
- First of all you have download opera v4.2 or v5.0 mini browser
- To download opera v4.2 mini browser CLICK HERE.
- To download opera v5.0 mini browser CLICK HERE.
- After downloading opera install this application it takes around 2-3 minitues to configured
- Activate AIRTEL Mobile Office -for that you have atleast 30 Rs Balance.
- After Mobile Office Activation -DONT OPEN/BROWSE ANY WEBSITE THROUGH BROWSER- EXCEPT OPERA v4.2 or v5.0 OTHER WISE AIRTEL WILL CHARGED YOU 15 RS. FOR THHAT DAY.
Now you can browse any site for free on opera mini ...
To Activate Mobile office for airtel mobile Contact customer care for how to activate airtel mobile office on my mobile..!!
Sunday, September 6, 2009
Download Game Fun Park Tycoon for Nokia 5800 XpressMusic and N97
Fun Park Tycoon is a Java game for Nokia 5800 XpressMusic, N97 and 5530 XpressMusic. Build a fun park by developing various kinds of rides and convenience facilities.
Expand the fun park, increase the number of rides but always keep the visitors happy. You get to the infinite mode, once you have played through the scenario mode.
 |  |
Game supports multiple languages: English, Francais, Italiano, Deutsch and Espanola. Fun Park Tycoon v1.0.8 game is published by SK Telecom, developed by Digissam and serviced by eFusion Info.
")
Download Game Mega Man III for Nokia 5800 XpressMusic and N97

Here is another cool Java game Mega Man III for Symbian S60 5th edition based mobiles e.g. Nokia 5800 XpressMusic, 5530 XpressMusic and N97. Mega Man III is full screen and complete touch supported game. Mega Man's role in the original story is to battle the mad scientist Dr. Wily and his ever-growing army of robots, and stop them from taking over the planet by using their own special abilities against them.
Utilizing his special Mega Blaster arm cannon and his ability to copy a defeated robot's special weapon, Mega Man must travel the world and traverse harsh environments in order to bring Wily's menace to an end.

With the help of his creator Dr. Light and his assorted robotic companions, Mega Man's eventual goal is to one day achieve "everlasting peace". Defeat the 8 robot masters to unlock the revisited levels. Defeat the revisited levels to unlock the Dr. Wily levels.

After defeating a boss, you can use his weapon by selecting it from the in-game menu. Each level is replayable and every time you start a level, you start with 3 lives.

Mega Man III has its own on-screen keyboard as shown in the above picture. Make sure you off the standard on-screen keyboard from the settings before starting this game. Mega Man III is developed by Capcom Mobile.
Download Game Bugs Bunny Rabbit Rescue for Nokia 5800 and N97
Here is another cool Java game Bugs Bunny Rabbit Rescue from Glu Mobile for Symbian S60 5th edition based mobiles e.g. Nokia 5800 XpressMusic, 5530 XpressMusic and N97.

Bugs Bunny Rabbit Rescue game has its own on-screen keypad. The game is based on Bugs Bunny fictional character who appears in the Looney Tunes and Merrie Melodies series of animated films produced by Leon Schlesinger Productions, which became Warner Bros. Cartoons in 1945.

What Pocket Gamer says - Bugs Bunny Rabbit Rescue is a turn-based game where you decide which object Bugs should use. The scene unravels regardless though, so if a character is due to enter stage left at a certain point, bashing a door to pieces, that'll happen whether you choose to use a frying pan or a pair of scissors that turn.

To get the scene playing as it should, you need to work out which is the right object to use at each point in time. As the title suggests, Bugs finds himself in a certain amount of peril in each scene, whether looking down the barrel of Fudd's shotgun or Marvin the Martian's laser pistol.

Keeping Bugs safe will normally involve either keeping whoever's after our protagonist dazed and confused or whacking him with something or other. Underneath the gloss, all there is to Bugs Bunny Rabbit Rescue is finding the order you need to click on a few different objects.

You have different gameplay: Marvin Attacks, Hare-Raising Castle, Elmer And The Wabbit, Attack of the 3 foot Martain and Living in The Wild West. The game supports multiple languages: English, Espanol, Francais, Deutsch, Italiano and Portguese.

Bugs Bunny Rabbit Rescue game has its own on-screen keypad. The game is based on Bugs Bunny fictional character who appears in the Looney Tunes and Merrie Melodies series of animated films produced by Leon Schlesinger Productions, which became Warner Bros. Cartoons in 1945.

What Pocket Gamer says - Bugs Bunny Rabbit Rescue is a turn-based game where you decide which object Bugs should use. The scene unravels regardless though, so if a character is due to enter stage left at a certain point, bashing a door to pieces, that'll happen whether you choose to use a frying pan or a pair of scissors that turn.

To get the scene playing as it should, you need to work out which is the right object to use at each point in time. As the title suggests, Bugs finds himself in a certain amount of peril in each scene, whether looking down the barrel of Fudd's shotgun or Marvin the Martian's laser pistol.

Keeping Bugs safe will normally involve either keeping whoever's after our protagonist dazed and confused or whacking him with something or other. Underneath the gloss, all there is to Bugs Bunny Rabbit Rescue is finding the order you need to click on a few different objects.

You have different gameplay: Marvin Attacks, Hare-Raising Castle, Elmer And The Wabbit, Attack of the 3 foot Martain and Living in The Wild West. The game supports multiple languages: English, Espanol, Francais, Deutsch, Italiano and Portguese.
Subscribe to:
Comments (Atom)