The Internet has transformed society in so many ways, and that’s bound to continue. The aim of our Big Tent events is to bring together people with diverse views to debate some of the hot-button issues that transformation raises.
This week we hosted our first Big Tent event stateside at the Computer History Museum in Mountain View, Calif. The theme was Digital Citizenship, and over the course of the day we discussed child safety online, the most effective ways to incorporate technology with education and what governments and civil society can do to maintain a responsible and innovative web.
The policymakers, commentators and industry members who attended heard from a variety of speakers, from child prodigy and literacy evangelist Adora Svitak to filmmaker and Webby Awards founder Tiffany Shlain. Wendy Kopp, the CEO and founder of Teach for America, gave a keynote about the need to integrate technology into education thoughtfully, not as a panacea, but rather within a greater context that supports critical thinking and other crucial curriculum goals. In a fireside chat with David Drummond, Jennifer Pahlka, the founder and executive director of Code for America (which takes the idea of skilled service from Teach for America and applies it to programmers) laid out her vision for a growing corps of young coder volunteers with an “agile, maker-and-doer mentality” that can help local governments better serve their citizens, and help citizens better participate in their democracy. “Instead of a chorus of voices,” she said, “I’d like to see a chorus of hands.”
We also launched a new Big Tent YouTube channel with a collection of content from past Big Tents and information about upcoming events around the world. Visit the channel to watch speaker videos, participate in the debate via the comments, get more information on the presenters and see how different communities approach many of the same issues. Stay tuned for future Big Tents, both here and abroad.
Saturday, March 31, 2012
Friday, March 30, 2012
Google App Engine Research Awards for scientific discovery
Since its launch four years ago, Google App Engine has been the platform for innovative and diverse applications. Today, Google’s University Relations team is inviting academic researchers to explore App Engine as a platform for their research activities through a new program: the Google App Engine Research Awards.
These research awards provide an opportunity for university faculty to experiment with App Engine, which provides services for building and hosting web applications on the same systems that power Google’s products and services. App Engine offers fast development and deployment, simple administration and built-in scalability -- it’s designed to adapt to large-scale data storage needs and sudden traffic spikes.
As part of Google’s ongoing commitment to support cutting-edge scientific research across the board, this call for applications welcomes university faculty’s proposals in all fields. Projects may focus on activities such as social or economic experiments, development of academic aids, analysis of gene sequence data, or using App Engine MapReduce to crunch large datasets, just to name a few.
This new award program will support up to 15 projects by providing App Engine credits in the amount of $60,000 to each project for one year. In its first year, the program is launched in a limited number of countries. Please see the RFP for details.
If your research has the potential to advance scientific discovery, generates heavy data loads, or needs a reliable platform for running large-scale apps, we encourage you to submit your proposal. Information on how to apply is available on the Google Research website. Applications will be accepted until 11:59 p.m. PST, May 11, 2012.
Thursday, March 29, 2012
Learning independence with Google Search features
Searches can become stories. Some are inspiring, some change the way we see the world and some just put a smile on our face. This is a story of how people can use Google to do something extraordinary. If you have a story, share it. - Ed.
We all have memories of the great teachers who shaped our childhood. They found ways to make the lightbulb go off in our heads, instilled in us a passion for learning and helped us realize our potential. The very best teachers were creative with the tools at their disposal, whether it was teaching the fundamentals of addition with Cheerios or the properties of carbon dioxide with baking soda and vinegar. As the Internet has developed, so too have the resources available for teachers to educate their students.
One teacher who has taken advantage of the web as an educational tool is Cheryl Oakes, a resource room teacher in Wells, Maine. She’s also been able to tailor the vast resources available on the web to each student’s ability. This approach has proven invaluable for Cheryl’s students, in particular 16-year-old Morgan, whose learning disability makes it daunting to sort through search results to find those webpages that she can comfortably read. Cheryl taught Morgan how to use the Search by Reading Level feature on Google Search, which enables Morgan to focus only on those results that are most understandable to her. To address the difficulty Morgan faces with typing, Cheryl introduced her to Voice Search, so Morgan can speak her queries into the computer. Morgan is succeeding in high school, and just registered to take her first college course this summer.
There’s a practically limitless amount of information available on the web, and with search features, you can find the content that is most meaningful for you. For more information, visit google.com/insidesearch/features.html.
We all have memories of the great teachers who shaped our childhood. They found ways to make the lightbulb go off in our heads, instilled in us a passion for learning and helped us realize our potential. The very best teachers were creative with the tools at their disposal, whether it was teaching the fundamentals of addition with Cheerios or the properties of carbon dioxide with baking soda and vinegar. As the Internet has developed, so too have the resources available for teachers to educate their students.
One teacher who has taken advantage of the web as an educational tool is Cheryl Oakes, a resource room teacher in Wells, Maine. She’s also been able to tailor the vast resources available on the web to each student’s ability. This approach has proven invaluable for Cheryl’s students, in particular 16-year-old Morgan, whose learning disability makes it daunting to sort through search results to find those webpages that she can comfortably read. Cheryl taught Morgan how to use the Search by Reading Level feature on Google Search, which enables Morgan to focus only on those results that are most understandable to her. To address the difficulty Morgan faces with typing, Cheryl introduced her to Voice Search, so Morgan can speak her queries into the computer. Morgan is succeeding in high school, and just registered to take her first college course this summer.
There’s a practically limitless amount of information available on the web, and with search features, you can find the content that is most meaningful for you. For more information, visit google.com/insidesearch/features.html.
Let’s fill London with startups...
London has become one of the world's great digital capitals. The Internet accounts for eight percent of the U.K. economy and has become, in these days of tough public finances, a welcome engine of economic growth.
We believe there is even more potential for entrepreneurs to energize the Internet economy in the U.K., and to help spur growth, today we’re opening Campus London , a seven story facility in the east London neighborhood known as Tech City. Google began as a startup in a garage. We want to empower the next generation of entrepreneurs to be successful by building and supporting a vibrant startup community. Our goal with Campus is to catalyze the startup ecosystem and build Britain's single largest community of startups under one roof.
The U.K.’s Chancellor of the Exchequer, the Rt. Hon. George Osborne MP, launched Campus at this morning's official opening. The Chancellor toured the building, meeting some of the entrepreneurs currently making their home in Campus and learning more about their innovations, ranging from fashion trendsetting websites to personalized London leisure guides. He then flipped the switch on a commemorative graffiti plaque.
Campus is a collaboration between Google and partners Central Working, Tech Hub, Seedcamp and Springboard. It will provide startups with workspace in an energizing environment and will also host daily events for and with the community. We will run a regular speaker series, alongside lectures and programing, as well as provide mentorship and training from local Google teams.
Visitors will have access to a cafe and co-working space, complete with high speed wifi. We welcome members of the startup community: entrepreneurs, investors, developers, designers, lawyers, accountants, etc. and hope that this informal, highly concentrated space will lead to chance meetings and interactions that will generate the ideas and partnerships that will drive new, innovative businesses.
The buzz around Campus from within the startup community has meant that today, on day one, Campus is already at 90% capacity, with more than 100 people on site and an additional 4,500 who have signed up online to visit.
We are looking forward to getting to know the community. East London is emerging as a world-leading entrepreneurial hub, and we’re excited to be a part of it. Take a photo tour of Campus here, and if you’d like to learn more, visit us at www.campuslondon.com.
Let’s fill this town with startups!
(Cross-posted from the European Public Policy blog)
We believe there is even more potential for entrepreneurs to energize the Internet economy in the U.K., and to help spur growth, today we’re opening Campus London , a seven story facility in the east London neighborhood known as Tech City. Google began as a startup in a garage. We want to empower the next generation of entrepreneurs to be successful by building and supporting a vibrant startup community. Our goal with Campus is to catalyze the startup ecosystem and build Britain's single largest community of startups under one roof.
The U.K.’s Chancellor of the Exchequer, the Rt. Hon. George Osborne MP, launched Campus at this morning's official opening. The Chancellor toured the building, meeting some of the entrepreneurs currently making their home in Campus and learning more about their innovations, ranging from fashion trendsetting websites to personalized London leisure guides. He then flipped the switch on a commemorative graffiti plaque.
Campus is a collaboration between Google and partners Central Working, Tech Hub, Seedcamp and Springboard. It will provide startups with workspace in an energizing environment and will also host daily events for and with the community. We will run a regular speaker series, alongside lectures and programing, as well as provide mentorship and training from local Google teams.
Visitors will have access to a cafe and co-working space, complete with high speed wifi. We welcome members of the startup community: entrepreneurs, investors, developers, designers, lawyers, accountants, etc. and hope that this informal, highly concentrated space will lead to chance meetings and interactions that will generate the ideas and partnerships that will drive new, innovative businesses.
The buzz around Campus from within the startup community has meant that today, on day one, Campus is already at 90% capacity, with more than 100 people on site and an additional 4,500 who have signed up online to visit.
We are looking forward to getting to know the community. East London is emerging as a world-leading entrepreneurial hub, and we’re excited to be a part of it. Take a photo tour of Campus here, and if you’d like to learn more, visit us at www.campuslondon.com.
Let’s fill this town with startups!
(Cross-posted from the European Public Policy blog)
Crossing the 50 billion km mark and giving Google Maps for Android a fresh look
Every day, millions of people turn to Google Maps for Android for free, voice-guided GPS navigation to guide them to their destination. So far, Navigation on Google Maps for Android has provided 50 billion kilometers of turn-by-turn directions, the equivalent of 130,000 trips to the moon, 334 trips to the sun, 10 trips to Neptune or 0.005 light years! When getting to your destination matters most, Google Maps for Android will get you there:
A new look for Navigation on Android 4.0+ phones
In today’s release of Google Maps 6.5 for Android we’ve redesigned the Navigation home screen in Android 4.0+ to make it easier to enter a new destination or select from recent and favorite locations by swiping left or right.
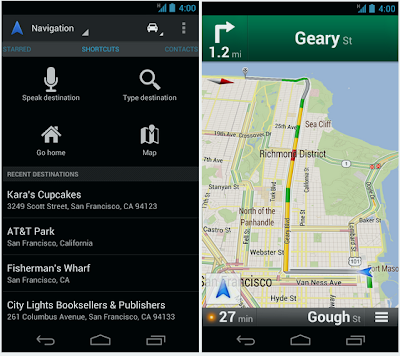
Left: New Navigation home screen Right: Navigation in Google Maps for Android
Crisper, faster maps for high pixel density devices
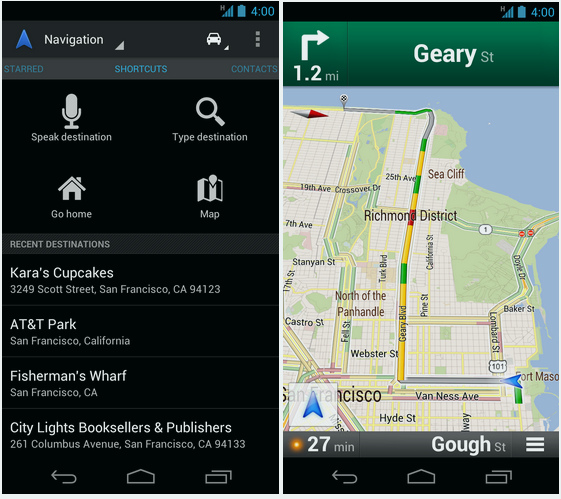
If your device has a high pixel density screen, such as those on Galaxy Nexus, Galaxy S II, Droid Razr and others, you’ll now get higher resolution map tiles that take better advantage of the pixels-per-inch on your screen. The result is a crisper, less cluttered map that is easier to read:

Left: Previous style Right:New style in Google Maps 6.5 for Android
Compare our new map on the right to the previous map on the left. The road network is easier to see, less obstructed by labels, and has more color contrast. At more zoomed-in levels, you’ll notice a more controlled amount of maps labels to avoid cluttering the map and blocking out street names. The new style also helps maps react faster to panning, zooming and twisting.
You'll start seeing the new style as you navigate around new areas on the map; however, you can see these changes immediately by clearing your cache from the Maps settings.
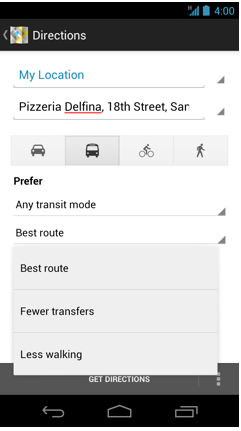
Pick your preferred public transit mode and route option
Google Maps 6.5 for Android now lets you choose to prioritize a particular transit mode (such as the bus or subway) and route option (like taking the recommended route, one with fewer transfers or one with less walking). Whether you just need to get somewhere as fast as possible, or you want to avoid the risk of a missed connection or you prefer not to tire your legs, you can get the transit directions that best suit you. Transit directions and schedules are available for 475 cities around the world.

To start using Google Maps 6.5 for Android, download the update from Google Play. Learn more about how to use other great features of Google Maps for Android on the redesigned Google Maps YouTube channel that has 12 new videos available today.
(Cross-posted on the Lat Long blog)
A new look for Navigation on Android 4.0+ phones
In today’s release of Google Maps 6.5 for Android we’ve redesigned the Navigation home screen in Android 4.0+ to make it easier to enter a new destination or select from recent and favorite locations by swiping left or right.
Crisper, faster maps for high pixel density devices
If your device has a high pixel density screen, such as those on Galaxy Nexus, Galaxy S II, Droid Razr and others, you’ll now get higher resolution map tiles that take better advantage of the pixels-per-inch on your screen. The result is a crisper, less cluttered map that is easier to read:

Compare our new map on the right to the previous map on the left. The road network is easier to see, less obstructed by labels, and has more color contrast. At more zoomed-in levels, you’ll notice a more controlled amount of maps labels to avoid cluttering the map and blocking out street names. The new style also helps maps react faster to panning, zooming and twisting.
You'll start seeing the new style as you navigate around new areas on the map; however, you can see these changes immediately by clearing your cache from the Maps settings.
Pick your preferred public transit mode and route option
Google Maps 6.5 for Android now lets you choose to prioritize a particular transit mode (such as the bus or subway) and route option (like taking the recommended route, one with fewer transfers or one with less walking). Whether you just need to get somewhere as fast as possible, or you want to avoid the risk of a missed connection or you prefer not to tire your legs, you can get the transit directions that best suit you. Transit directions and schedules are available for 475 cities around the world.
To start using Google Maps 6.5 for Android, download the update from Google Play. Learn more about how to use other great features of Google Maps for Android on the redesigned Google Maps YouTube channel that has 12 new videos available today.
(Cross-posted on the Lat Long blog)
Wednesday, March 28, 2012
Giving you more insight into your Google Account activity
Every day we aim to make technology so simple and intuitive that you stop thinking about it—we want Google to work so well, it just blends into your life. But sometimes it’s helpful to step back and take stock of what you’re doing online.
Today we’re introducing Account Activity, a new feature in your Google Account. If you sign up, each month we’ll send you a link to a password-protected report with insights into your signed-in use of Google services.
For example, my most recent Account Activity report told me that I sent 5 percent more email than the previous month and received 3 percent more. An Italian hotel was my top Gmail contact for the month. I conducted 12 percent more Google searches than in the previous month, and my top queries reflected the vacation I was planning: [rome] and [hotel].
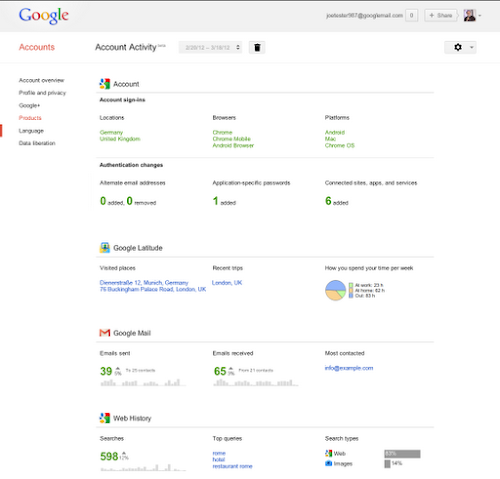
Knowing more about your own account activity also can help you take steps to protect your Google Account. For example, if you notice sign-ins from countries where you haven’t been or devices you’ve never owned, you can change your password immediately and sign up for the extra level of security provided by 2-step verification.
Account Activity is a complement to other tools like the Google Dashboard, which shows you what information is stored in your Google Account, and the Ads Preferences Manager, which lets you control the way Google tailors ads to your interests.
Give Account Activity a try, and tell us what you think by clicking on the “Send feedback” button in the lower right corner of your report. Over the next few months, we plan to incorporate more Google services. Meanwhile, we hope this feature helps you better understand and manage your information on Google.
Update March 30: Added information about related tools.
Today we’re introducing Account Activity, a new feature in your Google Account. If you sign up, each month we’ll send you a link to a password-protected report with insights into your signed-in use of Google services.
For example, my most recent Account Activity report told me that I sent 5 percent more email than the previous month and received 3 percent more. An Italian hotel was my top Gmail contact for the month. I conducted 12 percent more Google searches than in the previous month, and my top queries reflected the vacation I was planning: [rome] and [hotel].

Click the image for a larger version
Knowing more about your own account activity also can help you take steps to protect your Google Account. For example, if you notice sign-ins from countries where you haven’t been or devices you’ve never owned, you can change your password immediately and sign up for the extra level of security provided by 2-step verification.
Account Activity is a complement to other tools like the Google Dashboard, which shows you what information is stored in your Google Account, and the Ads Preferences Manager, which lets you control the way Google tailors ads to your interests.
Give Account Activity a try, and tell us what you think by clicking on the “Send feedback” button in the lower right corner of your report. Over the next few months, we plan to incorporate more Google services. Meanwhile, we hope this feature helps you better understand and manage your information on Google.
Update March 30: Added information about related tools.
Impact of Organic Ranking on Ad Click Incrementality
In 2011, Google released a Search Ads Pause research study which showed that 89% of the clicks from search ads are incremental, i.e., 89% of the visits to the advertiser’s site from ad-clicks are not replaced by organic clicks when the search ads are paused. In a follow up to the original study, we address two main questions: (1) how often is an ad impression accompanied by an associated organic result (i.e., organic result for the same advertiser)? and (2) how does the incrementality of the ad clicks vary with the rank of advertiser’s organic results?
A meta-analysis of 390 Search Ads Pause studies highlighted the limited opportunity for clicks from organic search results to substitute for ad clicks when search ads are turned off. We found that on average, 81% of ad impressions and 66% of ad clicks occur in the absence of an associated organic result on the first page of search results. In addition, we found that on average, 50% of the ad clicks that occur with a top rank organic result are incremental. The estimate for average incrementality of the ad clicks increases when the rank is lower; 82% of the ad clicks are incremental when the associated organic search result is between ranks 2 and 4, and 96% of the ad clicks are incremental when the advertiser’s organic result ranked lower than 4 (i.e., 5 and below).
While these findings provide guidance on overall trends, results for individual advertisers may vary. It’s also important to note that the study focuses on clicks rather than conversions. We recommend that advertisers employ randomized experiments (e.g., geo-based experiments) to better quantify the incremental traffic and lift in conversions from the search ad campaigns and that they use the value-per-click calculations in the original search ads pause study to determine the level of investment on their search ads.
For more information, find the full study here.
Take a train through the Swiss Alps with Street View
For the first time, you can ride a train on Street View. Through a partnership with UNESCO and Rhaetian Railways, we captured 75.8 miles/122 km of the famous UNESCO World Heritage Albula/Bernina railway line with Street View cameras. Starting today, in addition to accessing the imagery from directly within Google Maps, you can also find the collection in our new gallery.
Like our trip to the Amazon, this Swiss mountain journey also began last year, when we attached the Street View trike to the wagon of a Rhaetian Railway train. From the very front of the train, the trike took 360-degree images along the expansive track.
You can watch the video of how we did it here, and for more Street View collections around the world, visit our updated Street View gallery.
Enjoy the ride!
(Cross-posted on the Lat Long blog)
Like our trip to the Amazon, this Swiss mountain journey also began last year, when we attached the Street View trike to the wagon of a Rhaetian Railway train. From the very front of the train, the trike took 360-degree images along the expansive track.
You can watch the video of how we did it here, and for more Street View collections around the world, visit our updated Street View gallery.
Enjoy the ride!
(Cross-posted on the Lat Long blog)
Tuesday, March 27, 2012
Explore Mandela’s archives online
Last year we announced a $1.25 million grant to the Nelson Mandela Centre of Memory to help preserve and digitize thousands of archival documents, photographs and videos about Nelson Mandela. Based in Johannesburg, South Africa, the Nelson Mandela Centre of Memory (NMCM) is committed to documenting the life and times of one of the world's greatest statesmen and spreading his story to promote social justice throughout the world.
Today, the Mandela archive has become a reality. Along with historians, educationalists, researchers, activists and many others around the world, you can access a wealth of information and knowledge about the life and legacy of this extraordinary African leader. The new online multimedia archive includes Mandela’s correspondence with family, comrades and friends, diaries written during his 27 years of imprisonment, and notes he made while leading the negotiations that ended apartheid in South Africa. The archive will also include the earliest-known photo of Mr. Mandela and never-before seen drafts of Mr. Mandela's manuscripts for the sequel to his autobiography Long Walk to Freedom.
We’ve worked closely with the NMCM to create an interactive online experience which we hope will inspire you as much as us. You can search and browse the archives to explore different parts of Mandela’s life and work in depth: Early Life, Prison Years, Presidential Years, Retirement, Books for Mandela, Young People and My Moments with a Legend.
For example, you might be interested in Nelson Mandela’s personal memories of the time he was incarcerated and click into the Prison Years exhibit. You can immediately see a curated set of materials threaded together into a broader narrative. These include handwritten notes on his desk calendars, which show, for example, that he met President F.W. De Klerk for the first time on December 13, 1989 for two and a half hours in prison; the Warrants of Committal issued by the Supreme Court which sent him to prison; the earliest known photo of Nelson Mandela’s prison cell on Robben Island circa 1971; and a personal letter written from prison in 1963 to his daughters, Zeni and Zindzi, after their mother was arrested, complete with transcript.
From there, you might want to see all the letters held by the archive, and click “See more” in the letters category, where you can discover all personal letters or use the time filter to explore his diaries and calendars written between 1988 and 1998, where you can see that in the last page of the last diary, he met with President Yoweri Kaguta Museveni of Uganda to exchange ideas about the situation in northern Uganda. If you were a researcher, you can search through various fragments of Madiba’s memory that relate to Ahmed Kathrada, his long-time comrade, politician and anti-apartheid activist, where you can find photos, videos, manuscripts and letters that relate to him.
Finally, by clicking into the exhibit, My Moments with a Legend, you can go beyond Madiba’s personal materials to get a diverse perspective through photos, videos and stories, via the memories of people like Archbishop Desmond Tutu, F.W. De Klerk and Nomfundo Walaza, a community worker.
The Nelson Mandela Digital Archive project is an initiative by the Nelson Mandela Centre of Memory and the Google Cultural Institute, which helps to preserve and promote our diverse cultural and historical heritage. Some of our other initiatives include the Art Project, digitizing the Dead Sea Scrolls and bringing the Yad Vashem Holocaust materials online.
You can start exploring the Nelson Mandela archive right now at archive.nelsonmandela.org. We hope you’ll be inspired by this influential leader—the face of South Africa’s transition to democracy.
Today, the Mandela archive has become a reality. Along with historians, educationalists, researchers, activists and many others around the world, you can access a wealth of information and knowledge about the life and legacy of this extraordinary African leader. The new online multimedia archive includes Mandela’s correspondence with family, comrades and friends, diaries written during his 27 years of imprisonment, and notes he made while leading the negotiations that ended apartheid in South Africa. The archive will also include the earliest-known photo of Mr. Mandela and never-before seen drafts of Mr. Mandela's manuscripts for the sequel to his autobiography Long Walk to Freedom.

We’ve worked closely with the NMCM to create an interactive online experience which we hope will inspire you as much as us. You can search and browse the archives to explore different parts of Mandela’s life and work in depth: Early Life, Prison Years, Presidential Years, Retirement, Books for Mandela, Young People and My Moments with a Legend.
For example, you might be interested in Nelson Mandela’s personal memories of the time he was incarcerated and click into the Prison Years exhibit. You can immediately see a curated set of materials threaded together into a broader narrative. These include handwritten notes on his desk calendars, which show, for example, that he met President F.W. De Klerk for the first time on December 13, 1989 for two and a half hours in prison; the Warrants of Committal issued by the Supreme Court which sent him to prison; the earliest known photo of Nelson Mandela’s prison cell on Robben Island circa 1971; and a personal letter written from prison in 1963 to his daughters, Zeni and Zindzi, after their mother was arrested, complete with transcript.

From there, you might want to see all the letters held by the archive, and click “See more” in the letters category, where you can discover all personal letters or use the time filter to explore his diaries and calendars written between 1988 and 1998, where you can see that in the last page of the last diary, he met with President Yoweri Kaguta Museveni of Uganda to exchange ideas about the situation in northern Uganda. If you were a researcher, you can search through various fragments of Madiba’s memory that relate to Ahmed Kathrada, his long-time comrade, politician and anti-apartheid activist, where you can find photos, videos, manuscripts and letters that relate to him.
Finally, by clicking into the exhibit, My Moments with a Legend, you can go beyond Madiba’s personal materials to get a diverse perspective through photos, videos and stories, via the memories of people like Archbishop Desmond Tutu, F.W. De Klerk and Nomfundo Walaza, a community worker.

The Nelson Mandela Digital Archive project is an initiative by the Nelson Mandela Centre of Memory and the Google Cultural Institute, which helps to preserve and promote our diverse cultural and historical heritage. Some of our other initiatives include the Art Project, digitizing the Dead Sea Scrolls and bringing the Yad Vashem Holocaust materials online.
You can start exploring the Nelson Mandela archive right now at archive.nelsonmandela.org. We hope you’ll be inspired by this influential leader—the face of South Africa’s transition to democracy.
A new kind of summer job: open source coding with Google Summer of Code
It's only Spring Break for most college students, but summer vacation will be here before you know it. Instead of getting stuck babysitting your little sister or mowing your neighbor's lawn, apply for Google Summer of Code and spend the summer of 2012 earning money writing code for open source projects.
Google Summer of Code is a global program that gives university students a stipend to write code for open source projects over a three month period. Accepted students are paired with a mentor from the participating projects, gaining exposure to real-world software development and the opportunity for future employment in areas related to their academic pursuits. Best of all, more source code is created and released for the use and benefit of all.
For the past ten days, interested students have had the opportunity to review the ideas pages for this year’s 180 accepted projects and research which projects they would like to contribute to this year. We hope all interested students will apply! Submit your proposal to the mentoring organizations via the Google Summer of Code program website from today through Friday, April 6 at 19:00 UTC.

Google Summer of Code is a highly competitive program with a limited number of spots. Students should consult the Google Summer of Code student manual for suggestions on how to write a quality proposal that will grab the attention of the mentoring organizations. Multiple proposals are allowed but we highly recommend focusing on quality over quantity. The mentoring organizations have many proposals to review, so it is important to follow each organization’s specific guidelines or templates and we advise you to submit your proposal early so you can receive timely feedback.
For more tips, see a list of some helpful dos and don’ts for successful student participation written by a group of experienced Google Summer of Code administrators, our user’s guide for the program site, Frequently Asked Questions and timeline. You can also stay up-to-date on all things Google Summer of Code on our Google Open Source blog, mailing lists or on Internet relay chat at #gsoc on Freenode.
To learn more about Google Summer of Code, tune in to the Google Students page on Google+ next Monday, April 2 at 3:30pm PT for a Hangout on Air with open source programs manager Chris DiBona. He'll be talking about Google Summer of Code with other members of the open source team at Google. Submit your questions about the program between now and next Monday using the hashtag #gsochangout, and Chris and the open source team will answer them live during the Hangout On Air.
Good luck to all the open source coders out there, and remember to submit your proposals early—you only have until April 6!
Google Summer of Code is a global program that gives university students a stipend to write code for open source projects over a three month period. Accepted students are paired with a mentor from the participating projects, gaining exposure to real-world software development and the opportunity for future employment in areas related to their academic pursuits. Best of all, more source code is created and released for the use and benefit of all.
For the past ten days, interested students have had the opportunity to review the ideas pages for this year’s 180 accepted projects and research which projects they would like to contribute to this year. We hope all interested students will apply! Submit your proposal to the mentoring organizations via the Google Summer of Code program website from today through Friday, April 6 at 19:00 UTC.

Google Summer of Code is a highly competitive program with a limited number of spots. Students should consult the Google Summer of Code student manual for suggestions on how to write a quality proposal that will grab the attention of the mentoring organizations. Multiple proposals are allowed but we highly recommend focusing on quality over quantity. The mentoring organizations have many proposals to review, so it is important to follow each organization’s specific guidelines or templates and we advise you to submit your proposal early so you can receive timely feedback.
For more tips, see a list of some helpful dos and don’ts for successful student participation written by a group of experienced Google Summer of Code administrators, our user’s guide for the program site, Frequently Asked Questions and timeline. You can also stay up-to-date on all things Google Summer of Code on our Google Open Source blog, mailing lists or on Internet relay chat at #gsoc on Freenode.
To learn more about Google Summer of Code, tune in to the Google Students page on Google+ next Monday, April 2 at 3:30pm PT for a Hangout on Air with open source programs manager Chris DiBona. He'll be talking about Google Summer of Code with other members of the open source team at Google. Submit your questions about the program between now and next Monday using the hashtag #gsochangout, and Chris and the open source team will answer them live during the Hangout On Air.
Good luck to all the open source coders out there, and remember to submit your proposals early—you only have until April 6!
Monday, March 26, 2012
Measuring to improve: comprehensive, real-world data center efficiency numbers
To paraphrase Lord Kelvin, if you don’t measure you can’t improve. Our data center operations team lives by this credo, and we take every opportunity to measure the performance of our facilities. In the same way that you might examine your electricity bill and then tweak the thermostat, we constantly track our energy consumption and use that data to make improvements to our infrastructure. As a result, our data centers use 50 percent less energy than the typical data center.
One of the measurements we track is PUE, or power usage effectiveness. PUE is a ratio of the total power used to run a data center to the amount used to power the servers. For instance, if a data center has a PUE of 2.0, that means that for every watt of energy that powers the servers, another watt powers the cooling, lighting and other systems. An ideal PUE would be 1.0.
In 2011, our trailing 12-month average PUE was approximately 1.14—an improvement from 1.16 in 2010. In other words, our data centers use only 14 percent additional power for all sources of overhead combined. To calculate this number we include everything that contributes to energy consumption in our data centers. That means that in addition to the electricity used to power the servers and cooling systems, we incorporate the oil and natural gas that heat our offices. We also account for system inefficiencies like transformer, cable and UPS losses and generator parasitic energy draw.
If we chose to use a simpler calculation—for instance, if we included only the data center and the cooling equipment—we could report a PUE as low as 1.06 at our most efficient location. But we want to be as comprehensive as possible in our measurements. You can see the difference in this graphic:

We’ve been publishing our PUE quarterly since 2008—in fact, we were the first company to do so, and are still the only one. Our numbers are based on actual production data taken from hundreds of meters installed throughout our data centers, not design specs or best-case scenarios. One way to think of it is comparing a car manufacturer’s mileage estimates for a new model car to the car’s real-life miles per gallon. We’re measuring real-world mileage so we can improve real-world efficiency.
Our 2011 numbers and more are available for closer examination on our data center site. We’ve learned a lot through building and operating our data centers, so we’ve also shared our best practices. These include steps like raising the temperature on the server floor and using the natural environment to cool the data center, whether it’s outside air or recycled water.
We’ve seen dramatic improvements in efficiency throughout the industry in recent years, but there’s still a lot we can do. Sharing comprehensive measurement data and ideas for improvement can help us all move forward.
One of the measurements we track is PUE, or power usage effectiveness. PUE is a ratio of the total power used to run a data center to the amount used to power the servers. For instance, if a data center has a PUE of 2.0, that means that for every watt of energy that powers the servers, another watt powers the cooling, lighting and other systems. An ideal PUE would be 1.0.
In 2011, our trailing 12-month average PUE was approximately 1.14—an improvement from 1.16 in 2010. In other words, our data centers use only 14 percent additional power for all sources of overhead combined. To calculate this number we include everything that contributes to energy consumption in our data centers. That means that in addition to the electricity used to power the servers and cooling systems, we incorporate the oil and natural gas that heat our offices. We also account for system inefficiencies like transformer, cable and UPS losses and generator parasitic energy draw.
If we chose to use a simpler calculation—for instance, if we included only the data center and the cooling equipment—we could report a PUE as low as 1.06 at our most efficient location. But we want to be as comprehensive as possible in our measurements. You can see the difference in this graphic:
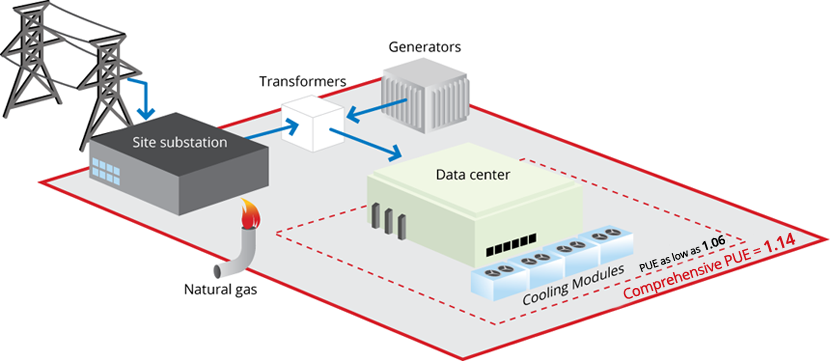
We’ve been publishing our PUE quarterly since 2008—in fact, we were the first company to do so, and are still the only one. Our numbers are based on actual production data taken from hundreds of meters installed throughout our data centers, not design specs or best-case scenarios. One way to think of it is comparing a car manufacturer’s mileage estimates for a new model car to the car’s real-life miles per gallon. We’re measuring real-world mileage so we can improve real-world efficiency.
Our 2011 numbers and more are available for closer examination on our data center site. We’ve learned a lot through building and operating our data centers, so we’ve also shared our best practices. These include steps like raising the temperature on the server floor and using the natural environment to cool the data center, whether it’s outside air or recycled water.
We’ve seen dramatic improvements in efficiency throughout the industry in recent years, but there’s still a lot we can do. Sharing comprehensive measurement data and ideas for improvement can help us all move forward.
Friday, March 23, 2012
Excellent Papers for 2011
UPDATE: Added Theo Vassilakis as an author for "Dremel: Interactive Analysis of Web-Scale Datasets"
Googlers across the company actively engage with the scientific community by publishing technical papers, contributing open-source packages, working on standards, introducing new APIs and tools, giving talks and presentations, participating in ongoing technical debates, and much more. Our publications offer technical and algorithmic advances, feature aspects we learn as we develop novel products and services, and shed light on some of the technical challenges we face at Google.
In an effort to highlight some of our work, we periodically select a number of publications to be featured on this blog. We first posted a set of papers on this blog in mid-2010 and subsequently discussed them in more detail in the following blog postings. In a second round, we highlighted new noteworthy papers from the later half of 2010. This time we honor the influential papers authored or co-authored by Googlers covering all of 2011 -- covering roughly 10% of our total publications. It’s tough choosing, so we may have left out some important papers. So, do see the publications list to review the complete group.
In the coming weeks we will be offering a more in-depth look at these publications, but here are some summaries:
Audio processing
“Cascades of two-pole–two-zero asymmetric resonators are good models of peripheral auditory function”, Richard F. Lyon, Journal of the Acoustical Society of America, vol. 130 (2011), pp. 3893-3904.
Lyon's long title summarizes a result that he has been working toward over many years of modeling sound processing in the inner ear. This nonlinear cochlear model is shown to be "good" with respect to psychophysical data on masking, physiological data on mechanical and neural response, and computational efficiency. These properties derive from the close connection between wave propagation and filter cascades. This filter-cascade model of the ear is used as an efficient sound processor for several machine hearing projects at Google.
Electronic Commerce and Algorithms
“Online Vertex-Weighted Bipartite Matching and Single-bid Budgeted Allocations”, Gagan Aggarwal, Gagan Goel, Chinmay Karande, Aranyak Mehta, SODA 2011.
The authors introduce an elegant and powerful algorithmic technique to the area of online ad allocation and matching: a hybrid of random perturbations and greedy choice to make decisions on the fly. Their technique sheds new light on classic matching algorithms, and can be used, for example, to pick one among a set of relevant ads, without knowing in advance the demand for ad slots on future web page views.
“Milgram-routing in social networks”, Silvio Lattanzi, Alessandro Panconesi, D. Sivakumar, Proceedings of the 20th International Conference on World Wide Web, WWW 2011, pp. 725-734.
Milgram’s "six-degrees-of-separation experiment" and the fascinating small world hypothesis that follows from it, have generated a lot of interesting research in recent years. In this landmark experiment, Milgram showed that people unknown to each other are often connected by surprisingly short chains of acquaintances. In the paper we prove theoretically and experimentally how a recent model of social networks, "Affiliation Networks", offers an explanation to this phenomena and inspires interesting technique for local routing within social networks.
“Non-Price Equilibria in Markets of Discrete Goods”, Avinatan Hassidim, Haim Kaplan, Yishay Mansour, Noam Nisan, EC, 2011.
We present a correspondence between markets of indivisible items, and a family of auction based n player games. We show that a market has a price based (Walrasian) equilibrium if and only if the corresponding game has a pure Nash equilibrium. We then turn to markets which do not have a Walrasian equilibrium (which is the interesting case), and study properties of the mixed Nash equilibria of the corresponding games.
HCI
“From Basecamp to Summit: Scaling Field Research Across 9 Locations”, Jens Riegelsberger, Audrey Yang, Konstantin Samoylov, Elizabeth Nunge, Molly Stevens, Patrick Larvie, CHI 2011 Extended Abstracts.
The paper reports on our experience with a basecamp research hub to coordinate logistics and ongoing real-time analysis with research teams in the field. We also reflect on the implications for the meaning of research in a corporate context, where much of the value may be less in a final report, but more in the curated impressions and memories our colleagues take away from the the research trip.
“User-Defined Motion Gestures for Mobile Interaction”, Jaime Ruiz, Yang Li, Edward Lank, CHI 2011: ACM Conference on Human Factors in Computing Systems, pp. 197-206.
Modern smartphones contain sophisticated sensors that can detect rich motion gestures — deliberate movements of the device by end-users to invoke commands. However, little is known about best-practices in motion gesture design for the mobile computing paradigm. We systematically studied the design space of motion gestures via a guessability study that elicits end-user motion gestures to invoke commands on a smartphone device. The study revealed consensus among our participants on parameters of movement and on mappings of motion gestures onto commands, by which we developed a taxonomy for motion gestures and compiled an end-user inspired motion gesture set. The work lays the foundation of motion gesture design—a new dimension for mobile interaction.
Information Retrieval
“Reputation Systems for Open Collaboration”, B.T. Adler, L. de Alfaro, A. Kulshreshtha , I. Pye, Communications of the ACM, vol. 54 No. 8 (2011), pp. 81-87.
This paper describes content based reputation algorithms, that rely on automated content analysis to derive user and content reputation, and their applications for Wikipedia and google Maps. The Wikipedia reputation system WikiTrust relies on a chronological analysis of user contributions to articles, metering positive or negative increments of reputation whenever new contributions are made. The Google Maps system Crowdsensus compares the information provided by users on map business listings and computes both a likely reconstruction of the correct listing and a reputation value for each user. Algorithmic-based user incentives ensure the trustworthiness of evaluations of Wikipedia entries and Google Maps business information.
Machine Learning and Data Mining
“Domain adaptation in regression”, Corinna Cortes, Mehryar Mohri, Proceedings of The 22nd International Conference on Algorithmic Learning Theory, ALT 2011.
Domain adaptation is one of the most important and challenging problems in machine learning. This paper presents a series of theoretical guarantees for domain adaptation in regression, gives an adaptation algorithm based on that theory that can be cast as a semi-definite programming problem, derives an efficient solution for that problem by using results from smooth optimization, shows that the solution can scale to relatively large data sets, and reports extensive empirical results demonstrating the benefits of this new adaptation algorithm.
“On the necessity of irrelevant variables”, David P. Helmbold, Philip M. Long, ICML, 2011
Relevant variables sometimes do much more good than irrelevant variables do harm, so that it is possible to learn a very accurate classifier using predominantly irrelevant variables. We show that this holds given an assumption that formalizes the intuitive idea that the variables are non-redundant. For problems like this it can be advantageous to add many additional variables, even if only a small fraction of them are relevant.
“Online Learning in the Manifold of Low-Rank Matrices”, Gal Chechik, Daphna Weinshall, Uri Shalit, Neural Information Processing Systems (NIPS 23), 2011, pp. 2128-2136.
Learning measures of similarity from examples of similar and dissimilar pairs is a problem that is hard to scale. LORETA uses retractions, an operator from matrix optimization, to learn low-rank similarity matrices efficiently. This allows to learn similarities between objects like images or texts when represented using many more features than possible before.
Machine Translation
“Training a Parser for Machine Translation Reordering”, Jason Katz-Brown, Slav Petrov, Ryan McDonald, Franz Och, David Talbot, Hiroshi Ichikawa, Masakazu Seno, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP '11).
Machine translation systems often need to understand the syntactic structure of a sentence to translate it correctly. Traditionally, syntactic parsers are evaluated as standalone systems against reference data created by linguists. Instead, we show how to train a parser to optimize reordering accuracy in a machine translation system, resulting in measurable improvements in translation quality over a more traditionally trained parser.
“Watermarking the Outputs of Structured Prediction with an application in Statistical Machine Translation”, Ashish Venugopal, Jakob Uszkoreit, David Talbot, Franz Och, Juri Ganitkevitch, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP).
We propose a general method to watermark and probabilistically identify the structured results of machine learning algorithms with an application in statistical machine translation. Our approach does not rely on controlling or even knowing the inputs to the algorithm and provides probabilistic guarantees on the ability to identify collections of results from one’s own algorithm, while being robust to limited editing operations.
“Inducing Sentence Structure from Parallel Corpora for Reordering”, John DeNero, Jakob Uszkoreit, Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Automatically discovering the full range of linguistic rules that govern the correct use of language is an appealing goal, but extremely challenging. Our paper describes a targeted method for discovering only those aspects of linguistic syntax necessary to explain how two different languages differ in their word ordering. By focusing on word order, we demonstrate an effective and practical application of unsupervised grammar induction that improves a Japanese to English machine translation system.
Multimedia and Computer Vision
“Kernelized Structural SVM Learning for Supervised Object Segmentation”, Luca Bertelli, Tianli Yu, Diem Vu, Burak Gokturk,Proceedings of IEEE Conference on Computer Vision and Pattern Recognition 2011.
The paper proposes a principled way for computers to learn how to segment the foreground from the background of an image given a set of training examples. The technology is build upon a specially designed nonlinear segmentation kernel under the recently proposed structured SVM learning framework.
“Auto-Directed Video Stabilization with Robust L1 Optimal Camera Paths”, Matthias Grundmann, Vivek Kwatra, Irfan Essa, IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011).
Casually shot videos captured by handheld or mobile cameras suffer from significant amount of shake. Existing in-camera stabilization methods dampen high-frequency jitter but do not suppress low-frequency movements and bounces, such as those observed in videos captured by a walking person. On the other hand, most professionally shot videos usually consist of carefully designed camera configurations, using specialized equipment such as tripods or camera dollies, and employ ease-in and ease-out for transitions. Our stabilization technique automatically converts casual shaky footage into more pleasant and professional looking videos by mimicking these cinematographic principles. The original, shaky camera path is divided into a set of segments, each approximated by either constant, linear or parabolic motion, using an algorithm based on robust L1 optimization. The stabilizer has been part of the YouTube Editor (youtube.com/editor) since March 2011.
“The Power of Comparative Reasoning”, Jay Yagnik, Dennis Strelow, David Ross, Ruei-Sung Lin, International Conference on Computer Vision (2011).
The paper describes a theory derived vector space transform that converts vectors into sparse binary vectors such that Euclidean space operations on the sparse binary vectors imply rank space operations in the original vector space. The transform a) does not need any data-driven supervised/unsupervised learning b) can be computed from polynomial expansions of the input space in linear time (in the degree of the polynomial) and c) can be implemented in 10-lines of code. We show competitive results on similarity search and sparse coding (for classification) tasks.
NLP
“Unsupervised Part-of-Speech Tagging with Bilingual Graph-Based Projections”, Dipanjan Das, Slav Petrov, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL '11), 2011, Best Paper Award.
We would like to have natural language processing systems for all languages, but obtaining labeled data for all languages and tasks is unrealistic and expensive. We present an approach which leverages existing resources in one language (for example English) to induce part-of-speech taggers for languages without any labeled training data. We use graph-based label propagation for cross-lingual knowledge transfer and use the projected labels as features in a hidden Markov model trained with the Expectation Maximization algorithm.
Networks
“TCP Fast Open”, Sivasankar Radhakrishnan, Yuchung Cheng, Jerry Chu, Arvind Jain, Barath Raghavan, Proceedings of the 7th International Conference on emerging Networking EXperiments and Technologies (CoNEXT), 2011.
TCP Fast Open enables data exchange during TCP’s initial handshake. It decreases application network latency by one full round-trip time, a significant speedup for today's short Web transfers. Our experiments on popular websites show that Fast Open reduces the whole-page load time over 10% on average, and in some cases up to 40%.
“Proportional Rate Reduction for TCP”, Nandita Dukkipati, Matt Mathis, Yuchung Cheng, Monia Ghobadi, Proceedings of the 11th ACM SIGCOMM Conference on Internet Measurement 2011, Berlin, Germany - November 2-4, 2011.
Packet losses increase latency of Web transfers and negatively impact user experience. Proportional rate reduction (PRR) is designed to recover from losses quickly, smoothly and accurately by pacing out retransmissions across received ACKs during TCP’s fast recovery. Experiments on Google Web and YouTube servers in U.S. and India demonstrate that PRR reduces the TCP latency of connections experiencing losses by 3-10% depending on response size.
Security and Privacy
“Automated Analysis of Security-Critical JavaScript APIs”, Ankur Taly, Úlfar Erlingsson, John C. Mitchell, Mark S. Miller, Jasvir Nagra, IEEE Symposium on Security & Privacy (SP), 2011.
As software is increasingly written in high-level, type-safe languages, attackers have fewer means to subvert system fundamentals, and attacks are more likely to exploit errors and vulnerabilities in application-level logic. This paper describes a generic, practical defense against such attacks, which can protect critical application resources even when those resources are partially exposed to attackers via software interfaces. In the context of carefully-crafted fragments of JavaScript, the paper applies formal methods and semantics to prove that these defenses can provide complete, non-circumventable mediation of resource access; the paper also shows how an implementation of the techniques can establish the properties of widely-used software, and find previously-unknown bugs.
“App Isolation: Get the Security of Multiple Browsers with Just One”, Eric Y. Chen, Jason Bau, Charles Reis, Adam Barth, Collin Jackson, 18th ACM Conference on Computer and Communications Security, 2011.
We find that anecdotal advice to use a separate web browser for sites like your bank is indeed effective at defeating most cross-origin web attacks. We also prove that a single web browser can provide the same key properties, for sites that fit within the compatibility constraints.
Speech
“Improving the speed of neural networks on CPUs”, Vincent Vanhoucke, Andrew Senior, Mark Z. Mao, Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011.
As deep neural networks become state-of-the-art in real-time machine learning applications such as speech recognition, computational complexity is fast becoming a limiting factor in their adoption. We show how to best leverage modern CPU architectures to significantly speed-up their inference.
“Bayesian Language Model Interpolation for Mobile Speech Input”, Cyril Allauzen, Michael Riley, Interspeech 2011.
Voice recognition on the Android platform must contend with many possible target domains - e.g. search, maps, SMS. For each of these, a domain-specific language model was built by linearly interpolating several n-gram LMs from a common set of Google corpora. The current work has found a way to efficiently compute a single n-gram language model with accuracy very close to the domain-specific LMs but with considerably less complexity at recognition time.
Statistics
“Large-Scale Parallel Statistical Forecasting Computations in R”, Murray Stokely, Farzan Rohani, Eric Tassone, JSM Proceedings, Section on Physical and Engineering Sciences, 2011.
This paper describes the implementation of a framework for utilizing distributed computational infrastructure from within the R interactive statistical computing environment, with applications to timeseries forecasting. This system is widely used by the statistical analyst community at Google for data analysis on very large data sets.
Structured Data
“Dremel: Interactive Analysis of Web-Scale Datasets”, Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Communications of the ACM, vol. 54 (2011), pp. 114-123.
Dremel is a scalable, interactive ad-hoc query system. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds. Besides continued growth internally to Google, Dremel now also backs an increasing number of external customers including BigQuery and UIs such as AdExchange front-end.
“Representative Skylines using Threshold-based Preference Distributions”, Atish Das Sarma, Ashwin Lall, Danupon Nanongkai, Richard J. Lipton, Jim Xu, International Conference on Data Engineering (ICDE), 2011.
The paper adopts principled approach towards representative skylines and formalizes the problem of displaying k tuples such that the probability that a random user clicks on one of them is maximized. This requires mathematically modeling (a) the likelihood with which a user is interested in a tuple, as well as (b) how one negotiates the lack of knowledge of an explicit set of users. This work presents theoretical and experimental results showing that the suggested algorithm significantly outperforms previously suggested approaches.
“Hyper-local, directions-based ranking of places”, Petros Venetis, Hector Gonzalez, Alon Y. Halevy, Christian S. Jensen, PVLDB, vol. 4(5) (2011), pp. 290-30.
Click through information is one of the strongest signals we have for ranking web pages. We propose an equivalent signal for raking real world places: The number of times that people ask for precise directions to the address of the place. We show that this signal is competitive in quality with human reviews while being much cheaper to collect, we also show that the signal can be incorporated efficiently into a location search system.
Systems
“Power Management of Online Data-Intensive Services”, David Meisner, Christopher M. Sadler, Luiz André Barroso, Wolf-Dietrich Weber, Thomas F. Wenisch, Proceedings of the 38th ACM International Symposium on Computer Architecture, 2011.
Compute and data intensive Web services (such as Search) are a notoriously hard target for energy savings techniques. This article characterizes the statistical hardware activity behavior of servers running Web search and discusses the potential opportunities of existing and proposed energy savings techniques.
“The Impact of Memory Subsystem Resource Sharing on Datacenter Applications”, Lingjia Tang, Jason Mars, Neil Vachharajani, Robert Hundt, Mary-Lou Soffa, ISCA, 2011.
In this work, the authors expose key characteristics of an emerging class of Google-style workloads and show how to enhance system software to take advantage of these characteristics to improve efficiency in data centers. The authors find that across datacenter applications, there is both a sizable benefit and a potential degradation from improperly sharing micro-architectural resources on a single machine (such as on-chip caches and bandwidth to memory). The impact of co-locating threads from multiple applications with diverse memory behavior changes the optimal mapping of thread to cores for each application. By employing an adaptive thread-to-core mapper, the authors improved the performance of the datacenter applications by up to 22% over status quo thread-to-core mapping, achieving performance within 3% of optimal.
“Language-Independent Sandboxing of Just-In-Time Compilation and Self-Modifying Code”, Jason Ansel, Petr Marchenko, Úlfar Erlingsson, Elijah Taylor, Brad Chen, Derek Schuff, David Sehr, Cliff L. Biffle, Bennet S. Yee, ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2011.
Since its introduction in the early 90's, Software Fault Isolation, or SFI, has been a static code technique, commonly perceived as incompatible with dynamic libraries, runtime code generation, and other dynamic code. This paper describes how to address this limitation and explains how the SFI techniques in Google Native Client were extended to support modern language implementations based on just-in-time code generation and runtime instrumentation. This work is already deployed in Google Chrome, benefitting millions of users, and was developed over a summer collaboration with three Ph.D. interns; it exemplifies how Research at Google is focused on rapidly bringing significant benefits to our users through groundbreaking technology and real-world products.
“Thialfi: A Client Notification Service for Internet-Scale Applications”, Atul Adya, Gregory Cooper, Daniel Myers, Michael Piatek,Proc. 23rd ACM Symposium on Operating Systems Principles (SOSP), 2011, pp. 129-142.
This paper describes a notification service that scales to hundreds of millions of users, provides sub-second latency in the common case, and guarantees delivery even in the presence of a wide variety of failures. The service has been deployed in several popular Google applications including Chrome, Google Plus, and Contacts.
Thursday, March 22, 2012
Ideas worthy of space travel: The YouTube Space Lab global winners
Can you teach an old spider new tricks? Could better understanding alien superbugs cure diseases on Earth? These are the questions that will be asked by the two winning experiments of YouTube Space Lab, the science competition that challenged students from 14 to 18 years old to design a science experiment that could be performed in space. Your votes and our expert judges chose the winners from thousands of entries from around the world. Experiments submitted by Dorothy and Sara, from Troy, Mich., U.S. (winners in the 14-16-year-old age group) and Amr from Alexandria, Egypt (winner in the 17-18-year-old age group) will be performed aboard the International Space Station and live streamed to the world on YouTube.
Sunita Williams—the NASA astronaut who’ll fly to the International Space Station later this year and perform the winning experiments live on YouTube—announced the global winners at a special ceremony in Washington, D.C., where the six regional winning teams were gathered. While in Washington, all the teams also took a ZERO-G weightless flight and a private tour of the the Udvar-Hazy Air & Space Museum.
In addition to having their experiments performed in space, Amr, Dorothy and Sara get to choose between one of two awesome space adventures: a trip to Japan to watch their experiment blast off in a rocket bound for the ISS or, once they’re 18 years old, a week-long astronaut course in Star City, Russia, the training center for Russian cosmonauts.
Subscribe to the YouTube Space Lab channel for all the best space playlists and to check out video of the winners on their ZERO-G flight. Stay tuned for the live stream from space, which will take place later this year.
Meet Amr from Alexandria, Egypt
Global Winner, 17-18-year-old age group:
Watch his entry: “Can you teach an old spider new tricks?”
Meet Dorothy and Sara from Troy, Mich., U.S.
Global Winners, 14-16-year-old age group:
Watch their entry: “Could alien superbugs cure diseases on Earth?”
Sunita Williams—the NASA astronaut who’ll fly to the International Space Station later this year and perform the winning experiments live on YouTube—announced the global winners at a special ceremony in Washington, D.C., where the six regional winning teams were gathered. While in Washington, all the teams also took a ZERO-G weightless flight and a private tour of the the Udvar-Hazy Air & Space Museum.
In addition to having their experiments performed in space, Amr, Dorothy and Sara get to choose between one of two awesome space adventures: a trip to Japan to watch their experiment blast off in a rocket bound for the ISS or, once they’re 18 years old, a week-long astronaut course in Star City, Russia, the training center for Russian cosmonauts.
Subscribe to the YouTube Space Lab channel for all the best space playlists and to check out video of the winners on their ZERO-G flight. Stay tuned for the live stream from space, which will take place later this year.
Visit the Amazon on World Forest Day with Street View
Last August, a few members of our Brazil and U.S. Street View and Google Earth Outreach teams were invited to the Amazon Basin to collect ground-level images of the rivers, forest and communities in the Rio Negro Reserve. Today, on World Forest Day, we’re making those images available through the Street View feature on Google Maps. Now anyone can experience the beauty and diversity of the Amazon.
Take a virtual boat ride down the main section of the Rio Negro, and float up into the smaller tributaries where the forest is flooded. Stroll along the paths of Tumbira, the largest community in the Reserve, or visit some of the other communities who invited us to share their lives and cultures. Enjoy a hike along an Amazon forest trail and see where Brazil nuts are harvested. You can even see a forest critter if you look hard enough!
This project was made possible in partnership with the Amazonas Sustainable Foundation (FAS), the local nonprofit conservation organization that invited us to the area. We used the Street View trike and a tripod camera with a fisheye lens—typically used to capture imagery of business interiors—to capture both the natural landscape and the local communities. In all, more than 50,000 still photos were stitched together to create these immersive, 360-degree panoramic views:
Many areas of the Amazon, including Rio Negro Reserve, are under the protection of the Brazilian government with restricted access to the public, so we hope that this Street View collection provides access to this special corner of the planet that many of us otherwise wouldn’t have the chance to experience. Together with FAS, we’re thrilled to help everyone from researchers and scientists to armchair explorers around the world learn more about the Amazon, and better understand how local communities there are working to preserve this unique environment for future generations.

Start exploring this portion of the Amazon and other collections around the world on the updated Street View site and gallery.
(Cross-posted on the Lat Long blog)
Tributary of the Rio Negro - View Larger Map
Take a virtual boat ride down the main section of the Rio Negro, and float up into the smaller tributaries where the forest is flooded. Stroll along the paths of Tumbira, the largest community in the Reserve, or visit some of the other communities who invited us to share their lives and cultures. Enjoy a hike along an Amazon forest trail and see where Brazil nuts are harvested. You can even see a forest critter if you look hard enough!
Amazon Rainforest - View Larger Map
This project was made possible in partnership with the Amazonas Sustainable Foundation (FAS), the local nonprofit conservation organization that invited us to the area. We used the Street View trike and a tripod camera with a fisheye lens—typically used to capture imagery of business interiors—to capture both the natural landscape and the local communities. In all, more than 50,000 still photos were stitched together to create these immersive, 360-degree panoramic views:

To do this directly from maps you can go to Brazil map and drag Pegman to the Rio Negro River
Start exploring this portion of the Amazon and other collections around the world on the updated Street View site and gallery.
(Cross-posted on the Lat Long blog)
Wednesday, March 21, 2012
Google at INFOCOM 2012
The computer networking community will get together in Orlando, Florida the week of March 25th for INFOCOM 2012, the Annual IEEE International Conference on Computer Communications.
At the conference, we will discuss topics such as traffic engineering, traffic anomaly detection, and random walk algorithms for topology-aware networks. We serve so much internet traffic to Google users and exchange so much data between our data centers that computer networking is naturally something we care about. As traffic grows with richer content (photos, video, ...), new modes of engagement (cloud computing, social networking, ...) and an increasing number of users, engineering and research efforts are necessary to help networks scale.
The following papers were co-authored by Googlers from offices around the world:
- Near-optimal random walk sampling in distributed networks by Atish Das Sarma, Anisur Molla, and Gopal Pandurangan
- How to split a flow by Tzvika Hartman, Avinatan Hassidim, Haim Kaplan, Danny Raz, and Michal Segalov
- Upward max-min fairness by Emilie Danna, Avinatan Hassidim, Haim Kaplan, Alok Kumar, Yishay Mansour, Danny Raz, and Michal Segalov (runner up for best paper)
- A practical algorithm for balancing the max-min fairness and throughput objectives in traffic engineering by Emilie Danna, Subhasree Mandal, and Arjun Singh
- Traffic anomaly detection based on the IP size distribution by Fabio Soldo and Ahmed Metwally
If you are attending, stop by and say hi!
Tuesday, March 20, 2012
Gamification for Improved Search Ranking for YouTube Topics
In earlier posts we discussed automatic ways to find the most talented emerging singers and the funniest videos using the YouTube Slam experiment. We created five “house” slams -- music, dance, comedy, bizarre, and cute -- which produce a weekly leaderboard not just of videos but also of YouTubers who are great at predicting what the masses will like. For example, last week’s cute slam winning video claims to be the cutest kitten in the world, beating out four other kittens, two puppies, three toddlers and an amazing duck who feeds the fish. With a whopping 620 slam points, YouTube user emoatali99 was our best connoisseur of cute this week. On the music side, it is no surprise that many of music slam’s top 10 videos were Adele covers. A Whitney Houston cover came out at the top this week, and music slam’s resident expert on talent had more than a thousand slam points. Well done! Check out the rest of the leaderboards for cute slam and music slam.
Can slam-style game mechanics incentivize our users to help improve the ranking of videos -- not just for these five house slams -- but for millions of other search queries and topics on YouTube? Gamification has previously been used to incentivize users to participate in non-game tasks such as image labeling and music tagging. How many votes and voters would we need for slam to do better than the existing ranking algorithm for topic search on YouTube?
As an experiment, we created new slams for a small number of YouTube topics (such as Latte Art Slam and Speed Painting Slam) using existing top 20 videos for these topics as the candidate pool. As we accumulated user votes, we evaluated the resulting YouTube Slam leaderboard for that topic vs the existing ranking on youtube.com/topics (baseline). Note that both the slam leaderboard and the baseline had the same set of videos, just in a different order.
What did we discover? It was no surprise that slam ranking performance had a high variance in the beginning and gradually improved as votes accumulated. We are happy to report that four of five topic slams converged within 1000 votes with a better leaderboard ranking than the existing YouTube topic search. In spite of small number of voters, Slam achieves better ranking partly because of gamification incentives and partly because it is based on machine learning, using:
- Preference judgement over a pair, not absolute judgement on a single video, and,
- Active solicitation of user opinion as opposed to passive observation. Due to what is called a “cold start” problem in data modeling, conventional (passive observation) techniques don’t work well on new items with little prior information. For any given topic, Slam’s improvement over the baseline in ranking of the “recent 20” set of videos was in fact better than the improvement in ranking of the “top 20” set.
Demographics and interests of the voters do affect slam leaderboard ranking, especially when the voter pool is small. An example is a Romantic Proposals Slam we featured on Valentine’s day last month. Men thought this proposal during a Kansas City Royals game was the most romantic, although this one where the man pretends to fall off a building came close. On the other hand, women rated this meme proposal in a restaurant as the best, followed by this movie theater proposal.
Encouraged by these results, we will soon be exploring slams for a few thousand topics to evaluate the utility of gamification techniques to YouTube topic search. Here are some of them: Chocolate Brownie, Paper Plane, Bush Flying, Stealth Technology, Stencil Graffiti, Yosemite National Park, and Stealth Technology.
Have fun slamming!
Thursday, March 15, 2012
We’ve gone mad for college hoops
It's March Madness and many basketball fans are turning to the web to research teams, coaches and players to build the perfect bracket. Being sports nerds ourselves, ever since the seeds announcement on Sunday we’ve been heads down in data, and with just a few hours left until first tip-off and brackets close, we’re attempting a buzzer beater: could search volume be a good indicator of game outcome?
We looked back at basketball search trends to see how Google would have performed if it had submitted a bracket for the past few tournaments. We've had our hits and misses over the years but in the spirit of the games and curiosity, we’ve decided to reveal our picks for the 2012 tournament based on search volume. Check back often to see how we’re doing.
Along with our official bracket, we’ve collected all the ways you can use Google to make your selections and stay connected with your teams and fellow fans throughout the tournament. Explore the full list on our College Hoops 2012 page.
Connect
We looked back at basketball search trends to see how Google would have performed if it had submitted a bracket for the past few tournaments. We've had our hits and misses over the years but in the spirit of the games and curiosity, we’ve decided to reveal our picks for the 2012 tournament based on search volume. Check back often to see how we’re doing.
Along with our official bracket, we’ve collected all the ways you can use Google to make your selections and stay connected with your teams and fellow fans throughout the tournament. Explore the full list on our College Hoops 2012 page.
Connect
- Join ESPN college basketball analyst Doug Gottlieb, along with fellow fans, in a series of hangouts beginning March 21 on the ESPN Google+ page to discuss bracket picks, game highlights and who the experts think will win “the big dance.”
- We’ve created a college hoops circle of NCAA teams you can follow on Google+. Whether a fan of +Kentucky, +Syracuse, +UNC or +Michigan State, you can stay up-to-date on your team and join players and coaches in a hangout.


- Keep up with your bracket picks by searching for [march madness] or individual teams like [duke basketball] to see real-time scores and schedules for the tournament.
- Download a complimentary copy of the Zagat guide Winning Hangouts for College Basketball Fans to find a place to watch the games and cheer on your favorite teams. The guide features trusted ratings and reviews for restaurants, sports bars and gastropubs in New York, Los Angeles, San Francisco, New Orleans, Boston, Atlanta, Chicago and Washington, D.C.
- Since chances are you can’t physically fly to every game around the U.S., take a virtual tour of the tournament locations via a customized map overlay in Google Earth and watch this video of 3D models of the stadiums where your favorite teams will be playing.
Helping the Hooch with water conservation at our Douglas County data center
If you’re familiar with the work of the Southern poet Sidney Lanier, you’ll know he wrote about the beauty of the Chattahoochee River in Georgia. “The Hooch,” as it’s known around here, starts up in the northeastern part of the state, runs through Atlanta and down into Alabama before emptying out into the Gulf of Mexico. Those of us who work in Google’s Douglas County, Ga. data center have a special fondness for the Chattahoochee because it’s an integral part of our ability to run a highly efficient facility.
Google’s data centers use half the energy of a typical data center in part because we rely on free cooling rather than energy hungry mechanical chillers. In Douglas County, like at most of our facilities, we use evaporative cooling, which brings cold water into the data center to cool the servers, then releases it as water vapor through cooling towers.
A typical data center can use hundreds of thousands of gallons of water a day. When we first built the Georgia facility in 2007, the water we used came from the local potable (drinking) water supply. But we soon realized that the water we used didn’t need to be clean enough to drink. So we talked to the Douglasville-Douglas County Water and Sewer Authority (known locally as the WSA) about setting up a system that uses reuse water—also known as grey- or recycled water—in our cooling infrastructure. With this system in place, we’re able to use recycled water for 100 percent of our cooling needs.
This video of the system includes never-before-seen footage of our Douglas County facility:
Here’s how it works: The WSA has a water treatment facility in Douglasville, Ga. that cleans wastewater from the local communities and releases it back into the Chattahoochee. We worked with the WSA to build a side-stream plant about five miles west of our data center that diverts up to 30 percent of the water that would have gone back into the river; instead we send it through the plant for treatment and then on to the data center. Any water that doesn’t evaporate during the cooling process then goes to an Effluent Treatment Plant located on-site. There, we treat the water once again to disinfect it, remove mineral solids and send it back out to the Chattahoochee—clean, clear and safe.
The Chattahoochee provides drinking water, public greenspace and recreational activities for millions of people. In fact, just two weeks ago it was the first river to be designated a National Water Trail in a new system announced by the Secretary of the Interior Ken Salazar—a system that encourages community stewardship of local waterways. We’re glad to do our part in creating an environmentally sustainable economy along the shores of the Hooch.
Google’s data centers use half the energy of a typical data center in part because we rely on free cooling rather than energy hungry mechanical chillers. In Douglas County, like at most of our facilities, we use evaporative cooling, which brings cold water into the data center to cool the servers, then releases it as water vapor through cooling towers.
A typical data center can use hundreds of thousands of gallons of water a day. When we first built the Georgia facility in 2007, the water we used came from the local potable (drinking) water supply. But we soon realized that the water we used didn’t need to be clean enough to drink. So we talked to the Douglasville-Douglas County Water and Sewer Authority (known locally as the WSA) about setting up a system that uses reuse water—also known as grey- or recycled water—in our cooling infrastructure. With this system in place, we’re able to use recycled water for 100 percent of our cooling needs.
This video of the system includes never-before-seen footage of our Douglas County facility:
Here’s how it works: The WSA has a water treatment facility in Douglasville, Ga. that cleans wastewater from the local communities and releases it back into the Chattahoochee. We worked with the WSA to build a side-stream plant about five miles west of our data center that diverts up to 30 percent of the water that would have gone back into the river; instead we send it through the plant for treatment and then on to the data center. Any water that doesn’t evaporate during the cooling process then goes to an Effluent Treatment Plant located on-site. There, we treat the water once again to disinfect it, remove mineral solids and send it back out to the Chattahoochee—clean, clear and safe.

The Chattahoochee provides drinking water, public greenspace and recreational activities for millions of people. In fact, just two weeks ago it was the first river to be designated a National Water Trail in a new system announced by the Secretary of the Interior Ken Salazar—a system that encourages community stewardship of local waterways. We’re glad to do our part in creating an environmentally sustainable economy along the shores of the Hooch.
Making our ads better for everyone
We believe that ads are useful and relevant information that can help you find what you’re looking for online—whether you’re comparing digital cameras or researching new cars. We also want you to be able to use Google and click on any ads that interest you with confidence. Just as we work hard to make Gmail free of spam and the Google Play Store free of malware, we’re committed to enforcing rigorous standards for the ads that appear on Google and on our partner sites.
Like all other Internet companies, we’re fighting a war against a huge number of bad actors—from websites selling counterfeit goods and fraudulent tickets to underground international operations trying to spread malware and spyware. We must remain vigilant because scammers will always try to find new ways to abuse our systems. Given the number of searches on Google and the number of legitimate businesses who rely on this system to reach users, our work to remove bad ads must be precise and at scale.
We recently made some improvements to help ensure the ads you see comply with our strict policies, so we wanted to give you an overview of both our principles and these new technologies.
Ads that harm users are not allowed on Google
We’ve always approached our ads system with trust and safety in mind. Our policies cover a wide range of issues across the globe in every country in which we do business. For example, our ads policies don’t allow ads for illegal products such as counterfeit goods or harmful products such as handguns or cigarettes. We also don’t allow ads with misleading claims (“lose weight guaranteed!”), fraudulent work-at-home scams (“get rich quick working from home!”) or unclear billing practices.
How it all works
With billions of ads submitted to Google every year, we use a combination of sophisticated technology and manual review to detect and remove these sorts of ads. We spend millions of dollars building technical architecture and advanced machine learning models to fight this battle. These systems are designed to detect and remove ads for malicious download sites that contain malware or a virus before these ads could appear on Google. Our automated systems also scan and review landing pages—the websites that people are taken to once they click—as well as advertiser accounts. When potentially objectionable ads are flagged by our automated systems, our policy specialists review the ads, sites and accounts in detail and take action.
Improvements to detection systems
Here are some important improvements that we’ve recently made to our systems:
We also routinely review and update the areas which our policies cover. For example, we recently updated our policy for ads related to short-term loans in order to protect people from misleading claims. For short-term loans, we require advertisers to disclose fine-print details such as overall fees and annual percentage rate, as well as implications for late and non-payment.
Bad ads are declining
The numbers show we’re having success. In 2011, advertisers submitted billions of ads to Google, and of those, we disabled more than 130 million ads. And our systems continue to improve—in fact, in 2011 we reduced the percentage of bad ads by more than 50% compared with 2010. That means that our methods are working. We’re also catching the vast majority of these scam ads before they ever appear on Google or on any of our partner networks. For example, in 2011, we shut down approximately 150,000 accounts for attempting to advertise counterfeit goods, and more than 95% of these accounts were discovered through our own detection efforts and risk models.
Here’s David Baker, Engineering Director, who can explain more about how we detect and remove scam ads:
What you can do to help
If you’re an advertiser, we encourage you to review our policies that aim to protect users, so you can help keep the web safe. For everyone else, our Good to Know site has lots of advice, including tips for avoiding scams anywhere on the Internet. You can also report ads you believe to be fraudulent or in violation of our policies and, if needed, file a complaint with the appropriate agency as listed in our Web Search Help Center.
Online advertising is the commercial lifeblood of the web, so it’s vital that people can trust the ads on Google and the Internet overall. We’ll keep posting more information here about our efforts, and developments, in this area.
Like all other Internet companies, we’re fighting a war against a huge number of bad actors—from websites selling counterfeit goods and fraudulent tickets to underground international operations trying to spread malware and spyware. We must remain vigilant because scammers will always try to find new ways to abuse our systems. Given the number of searches on Google and the number of legitimate businesses who rely on this system to reach users, our work to remove bad ads must be precise and at scale.
We recently made some improvements to help ensure the ads you see comply with our strict policies, so we wanted to give you an overview of both our principles and these new technologies.
Ads that harm users are not allowed on Google
We’ve always approached our ads system with trust and safety in mind. Our policies cover a wide range of issues across the globe in every country in which we do business. For example, our ads policies don’t allow ads for illegal products such as counterfeit goods or harmful products such as handguns or cigarettes. We also don’t allow ads with misleading claims (“lose weight guaranteed!”), fraudulent work-at-home scams (“get rich quick working from home!”) or unclear billing practices.
How it all works
With billions of ads submitted to Google every year, we use a combination of sophisticated technology and manual review to detect and remove these sorts of ads. We spend millions of dollars building technical architecture and advanced machine learning models to fight this battle. These systems are designed to detect and remove ads for malicious download sites that contain malware or a virus before these ads could appear on Google. Our automated systems also scan and review landing pages—the websites that people are taken to once they click—as well as advertiser accounts. When potentially objectionable ads are flagged by our automated systems, our policy specialists review the ads, sites and accounts in detail and take action.
Improvements to detection systems
Here are some important improvements that we’ve recently made to our systems:
- Improved “query watch” for counterfeit ads: While anyone can report counterfeit ads, we’ve widened our proactive monitoring of sensitive keywords and queries related to counterfeit goods which allows us to catch more counterfeit ads before they ever appear on Google
- New “risk model” to detect violations: Our computer scanning depends on detailed risk models to determine whether a particular ad may violate our policies, and we recently upgraded our engineering system with a new “risk model” that is even more precise in detecting advertisers who violate our policies
- Faster manual review process: Some ads need to be reviewed manually. To increase our response time in preventing ads from policy-violating advertisers, we sped up our internal processes and systems for manual reviews, enabling our specialists to be more precise and fast
- Twenty-four hour response time: We aim to respond within 24 hours upon receiving a reliable complaint about an ad to ensure that we’re reviewing ads in a timely fashion
We also routinely review and update the areas which our policies cover. For example, we recently updated our policy for ads related to short-term loans in order to protect people from misleading claims. For short-term loans, we require advertisers to disclose fine-print details such as overall fees and annual percentage rate, as well as implications for late and non-payment.
Bad ads are declining
The numbers show we’re having success. In 2011, advertisers submitted billions of ads to Google, and of those, we disabled more than 130 million ads. And our systems continue to improve—in fact, in 2011 we reduced the percentage of bad ads by more than 50% compared with 2010. That means that our methods are working. We’re also catching the vast majority of these scam ads before they ever appear on Google or on any of our partner networks. For example, in 2011, we shut down approximately 150,000 accounts for attempting to advertise counterfeit goods, and more than 95% of these accounts were discovered through our own detection efforts and risk models.
Here’s David Baker, Engineering Director, who can explain more about how we detect and remove scam ads:
What you can do to help
If you’re an advertiser, we encourage you to review our policies that aim to protect users, so you can help keep the web safe. For everyone else, our Good to Know site has lots of advice, including tips for avoiding scams anywhere on the Internet. You can also report ads you believe to be fraudulent or in violation of our policies and, if needed, file a complaint with the appropriate agency as listed in our Web Search Help Center.
Online advertising is the commercial lifeblood of the web, so it’s vital that people can trust the ads on Google and the Internet overall. We’ll keep posting more information here about our efforts, and developments, in this area.
Subscribe to:
Posts (Atom)